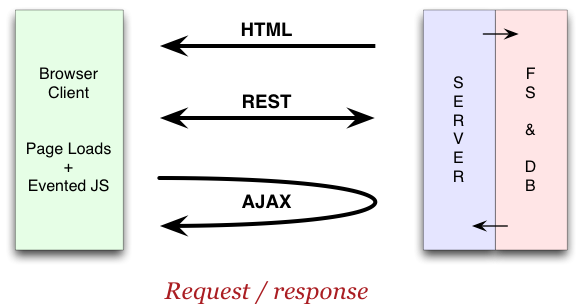
When you hook two devices up via wires, you’ve got essentially two options: parallel, i.e. one wire for each bit you want to transmit & receive (example: memory cards inside a PC). Or serial, where information gets sent across bit by bit over only a few wires (examples: ethernet, USB, I2C). Parallel can achieve very high speeds with little circuitry, but serial is more convenient and cheaper for large distances.
Serial communication is very common. The model even carries through to the way we think about the “command line” – a stream of characters typed in, followed by a stream of output characters. Not surprising, since terminals used to be connected via RS232 serial links.
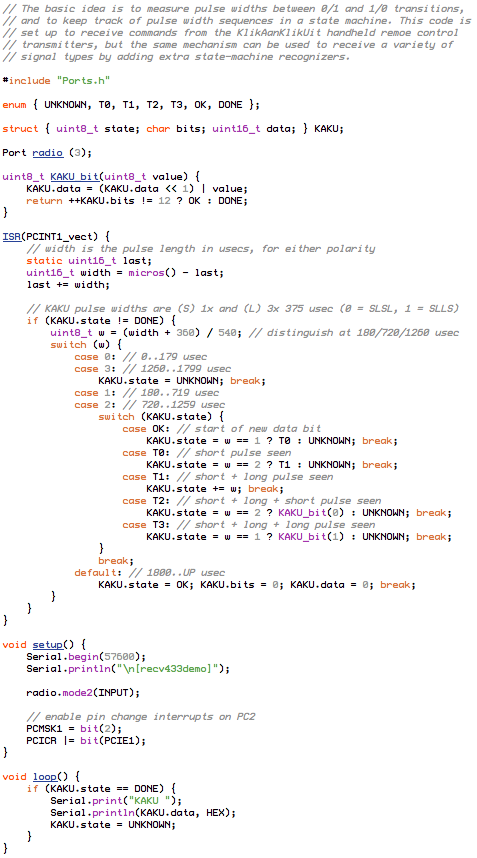
Wireless connections are also essentially serial: you rapidly turn a transmitter on and off (OOK), or you change its frequency of operation (FSK), to get the individual bits across.
But there’s a lot more to it than that.
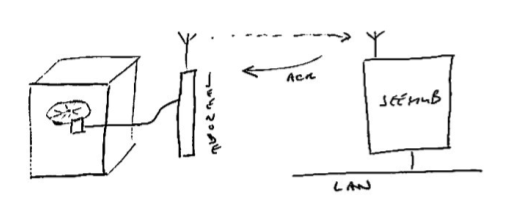
With two devices connected together, you get a peer-to-peer setup with a link which is dedicated for them. This means they can send whenever they please and things will work. The same can be done with wireless: as long as only two devices are involved, one device can send whenever it likes and the other will receive the signal just fine (within a certain range, evidently).
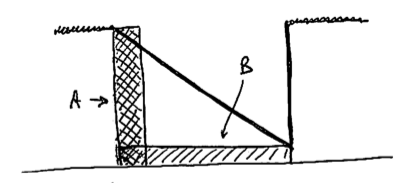
With such a peer-to-peer setup, the serial nature of the communication channel is obvious: A sends some characters, and B will receive them, in the same order and (almost) at the same time.
But what if you’ve got more than two devices? Ah, now it gets interesting…
With wires, you could do this:

It’s easy to set up, but it’s pretty expensive: lots of wires all over the place (N x (N-1) / 2 for N devices) plus lots of interfaces on each device (N-1). With 10 devices, that would be 45 wires and 90 interfaces!
Worse still, this is very hard to use with wireless, where each “wire” would need to be a dedicated frequency band.
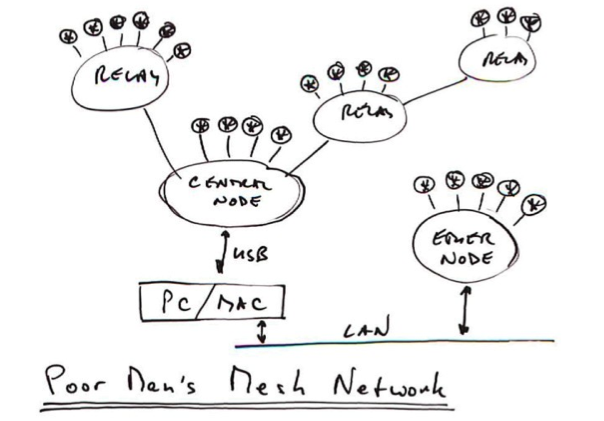
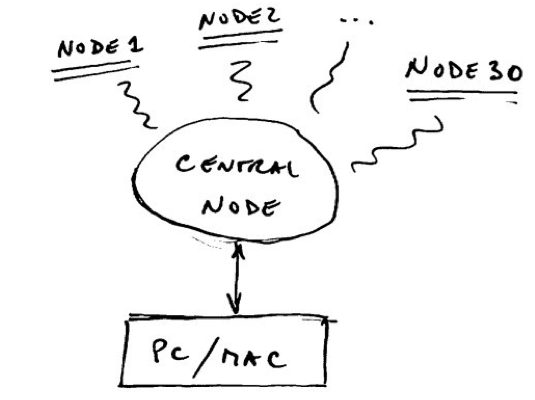
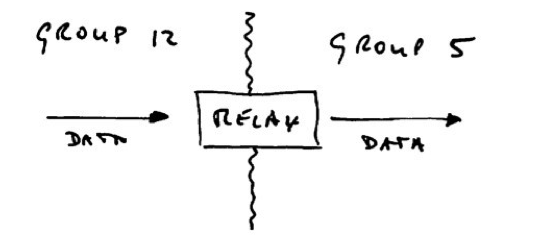
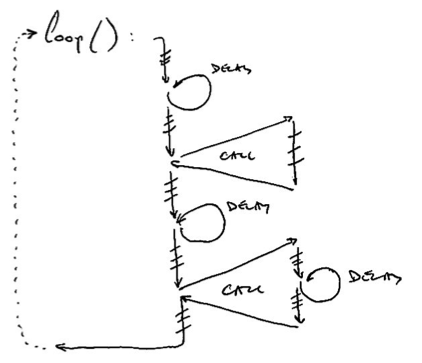
The solution is to share a single wire – called multi-drop:

Now there’s one wire, a couple of “taps”, and one interface per device. Much cheaper!
Trouble is, you’ve now created a “channel” which is no longer dedicated to each device (or “node” as it is usually called in such a context). They can’t just talk whenever they like anymore!
Whole new slew of issue now. How do you find out when the channel is available? What do you do when you can’t send something right away – save it up? How long? How much can you save up? What if someone else hijacked the channel and never stops transmitting? What if all nodes want to send more than the channel can handle? How do you get your information out to a specific node? Can all nodes listen to everything?
Welcome to the world of networking.
All of a sudden, simple one-on-one exchanges become quite complex. You’ll need more software to play nice on the channel. All nodes need the same software revision. And you’ve got to deal with being told “not now”.
Note that these issues apply to wired solution sharing the same channel (RS485, Canbus, USB, Ethernet) as well as all wireless networks.
Simple OOK transmitters used in weather station sensors just ignore the issue. They send whenever they want to, in an après moi le déluge fashion… (“what the heck, I don’t care whether my message arrives”). This usually works fairly well when transmissions are short, and when lost transmissions are no big deal – they’ll send out a new reading a few minutes later anyway.
Another aspect of this shotgun approach is that it’s a broadcast mechanism. The sending node transmits its messages into the air without interest as to who receives them, or whether there’s anyone listening even. All it needs to do is include a unique code, so that the receiver(s) will be able to tell who sent the message.
For weather sensors, the above is ok. For security / alarm purposes, it’s a bit unfortunate – missing an intrusion alert is not so great. So what the simplest systems do is to yell a bit louder: repeat the alert message many times, in the hope that at least one will arrive intact. No guarantees, yet some very common security systems seem to be happy with that level of reliability.
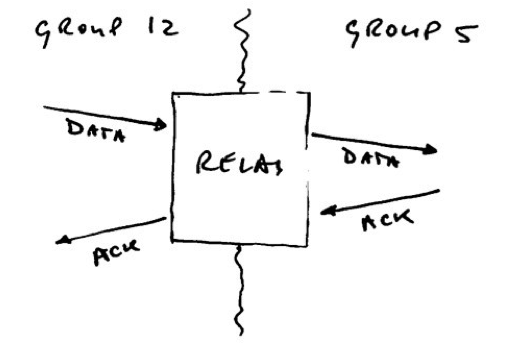
For more robust setups, you really need bi-directional communication, even if the payload only flows in one direction. Then each receiver can let the transmitter know when it got a packet intact.
There’s a lot more (software) complexity involved to use a channel effectively, to get data across reliably with “ACK” packets, to detect new and lost nodes, to deal with “congestion” and external causes of bad reception, etc.
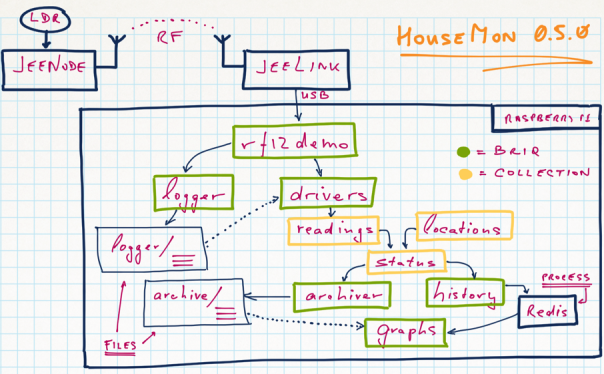
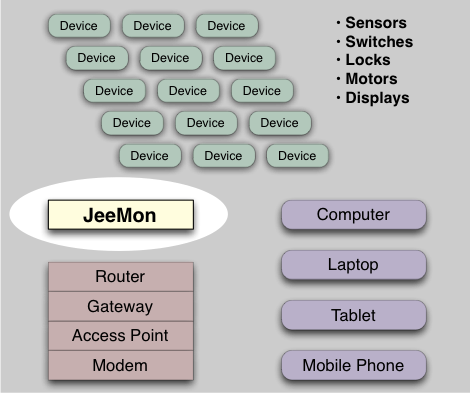
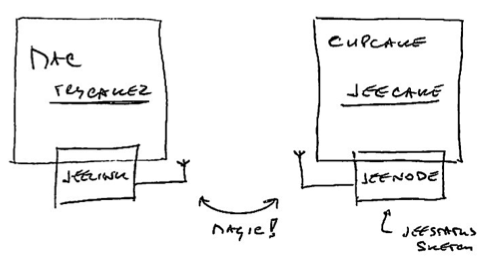
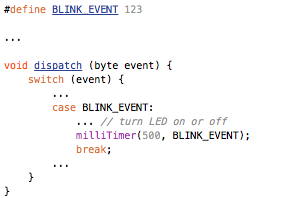
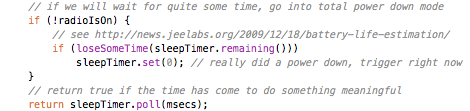
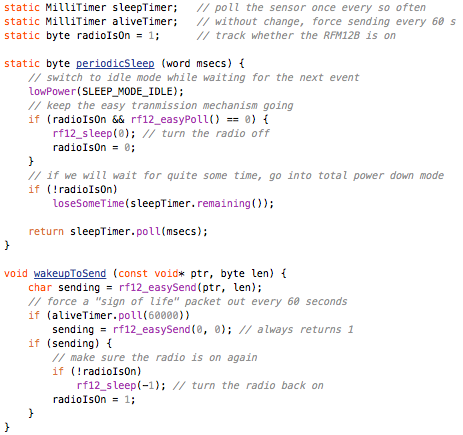
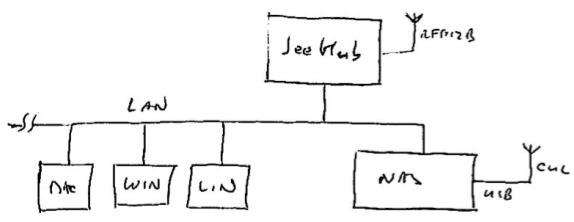
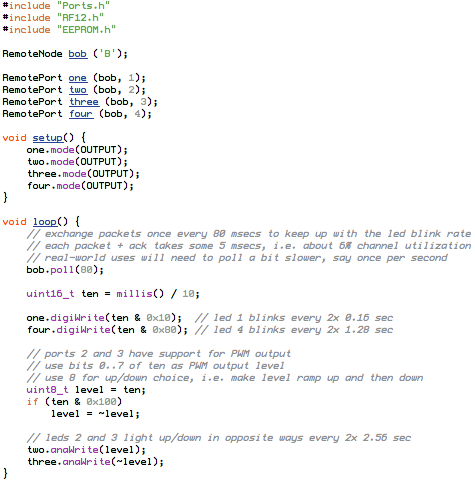
With JeeNodes and wireless comms via the RFM12B module, the basic RF12 driver is somewhere in the middle between unchecked uni-directional transmission and fully checked self-adapting configurations.
So what does this all mean for the “end user” ?
Well, first of all: wireless communication can fail. A node can be out of range, or a badly-behaved machine can be sending out RF interference to such an extent that nothing gets across no matter what nodes do. Wireless communication can fail, it’s as simple as that! But with bi-directional communication, at least all nodes can find out whether things work or not.
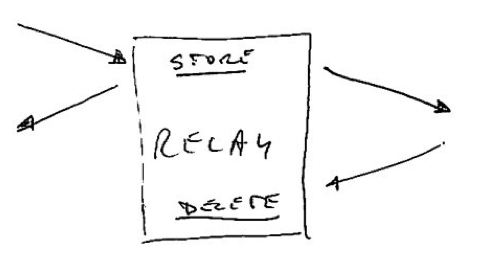
The second key property of communication via a shared channel, is that you can’t just send whenever you like. You have to be able to either save things up until later, or discard messages to let future ones through.
This means that treating a wireless channel as a serial link is really a very bad idea. Keep in mind that the baudrate can drop to zero – this means that you must be prepared to save up infinitely much data for re-transmission. And the more you intend to re-transmit later, the longer you’re going to have to need that channel when it becomes available. That will frustrate all the other nodes trying to do the same thing.
One way around this, is to use a RF link with very high data rates. That way there will be a lot of slack when nodes want to catch up. But then you still need to be able to buffer all that data in the first place. Not a great idea for limited devices such as an ATmega…
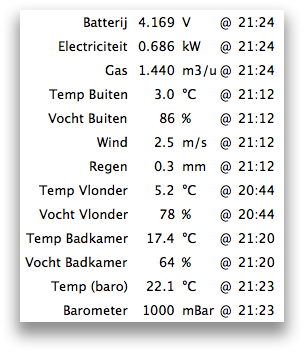
The better way is to design the system to work well with occasional loss of packets. Take an energy meter, for example: don’t sent the pulse or rotation trigger, but keep a count and send the current count value. That way, lost packets will not affect the accuracy of the results, they will merely be updated less frequently when the RF link is down.
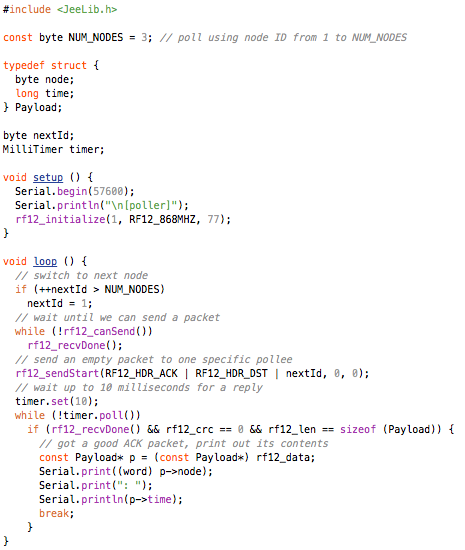
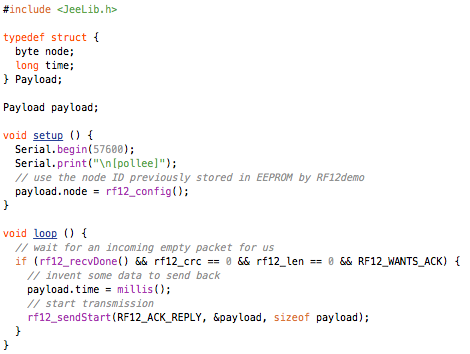
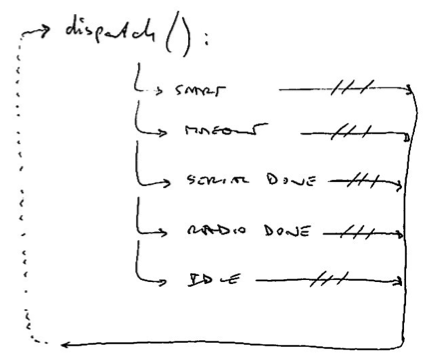
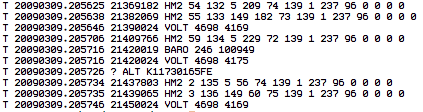
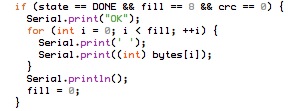
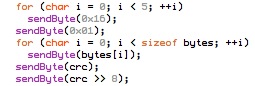
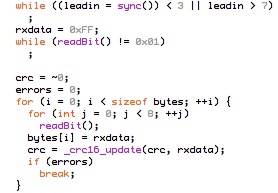
The RF12 driver used in JeeNodes was designed for the context of a little data, sent on a periodic basis. The difference with a serial link, is that you don’t get garbled text on the other side, but packets (i.e. chunks of data). All you need to keep in mind is that occasionally an entire packet won’t make it.
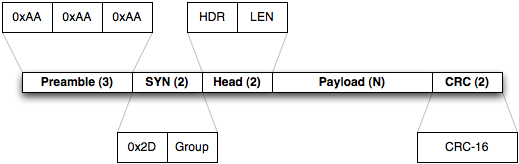
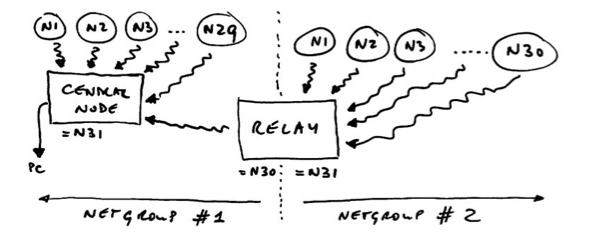
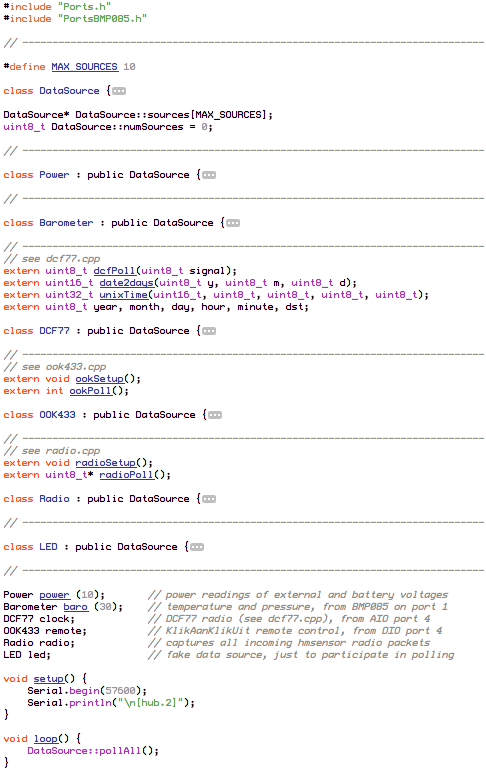
This design also deals with multiple nodes. Each incoming packet can have a “node ID” so receivers can tell everything apart. Packets never get mixed up or combined or split in any way. Each packet is a verified and consistent amount of data.
Couldn’t we implement a virtual serial link?
Well, yes – there are well-known techniques to implement a virtual circuit on top of a packet-based communication channel.
But doing so would be a bad idea, for reasons which have hopefully become clear from the above. A virtual circuit would either have to act as perfect channel (not feasible with finite data storage) or drop characters in unpredictable places. It is far more practical to impose a packet / chunk structure on the sender, and then be allowed to drop chunks with clearly-defined boundaries when the RF link is out of service or overloaded.
The moral of the story: think in packets when using JeeNode wireless comms – you’ll get a lot more done!
Update – see some good comments by John M below, about IP, UDP, TCP, and the OSI model which describes all the levels of abstraction involved with networking, and all the standard terminology.




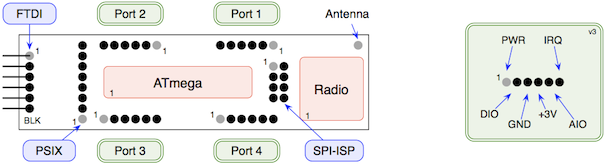




















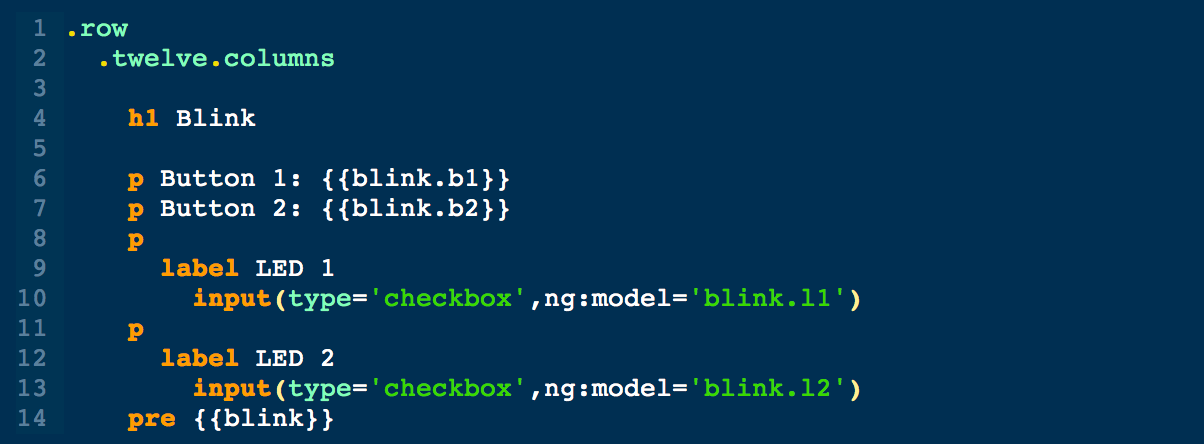
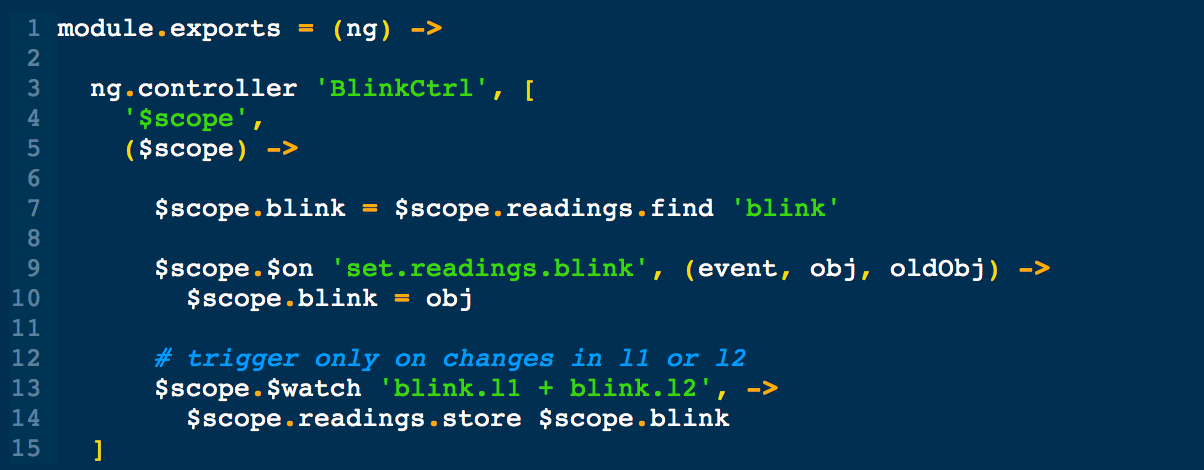
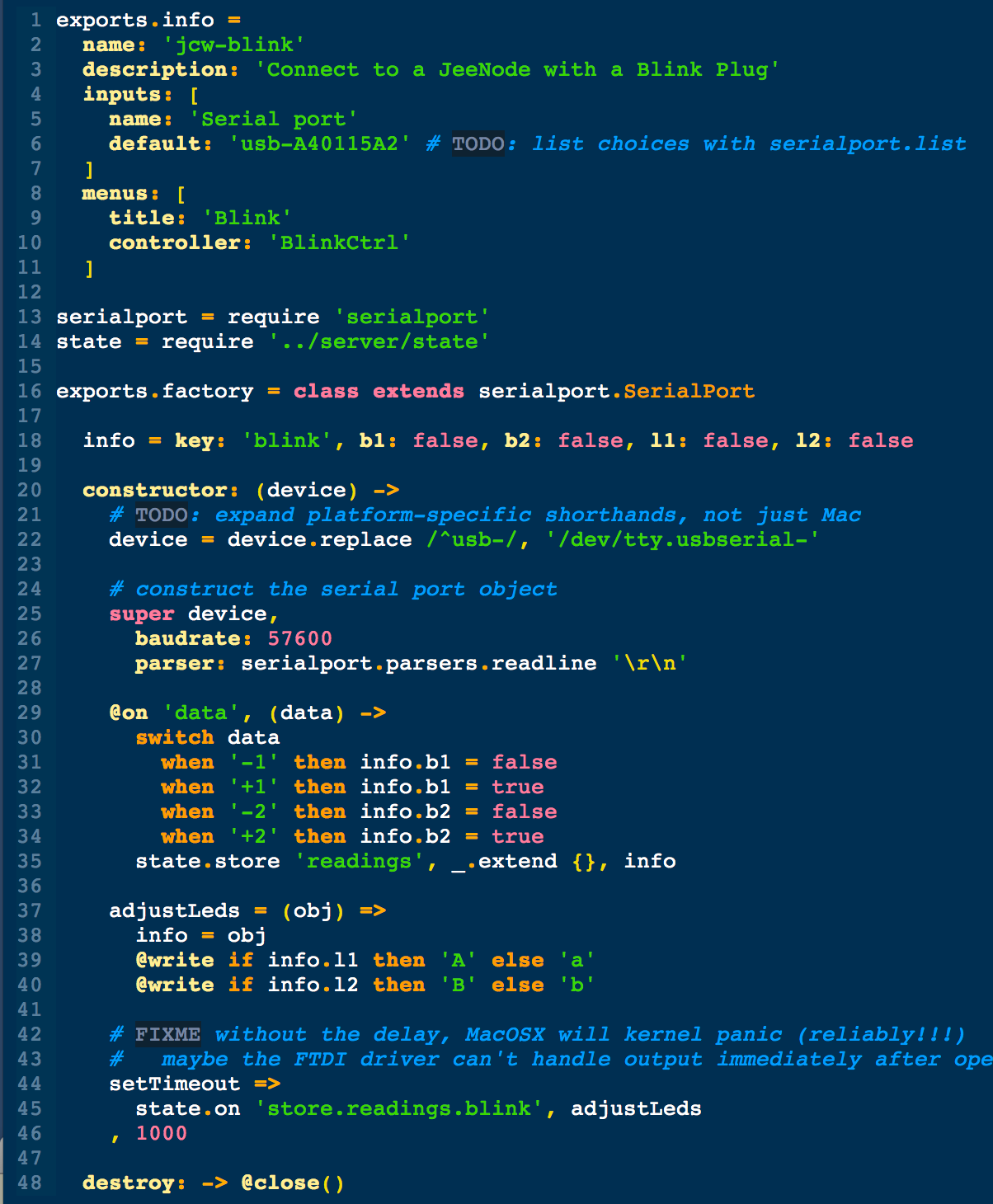








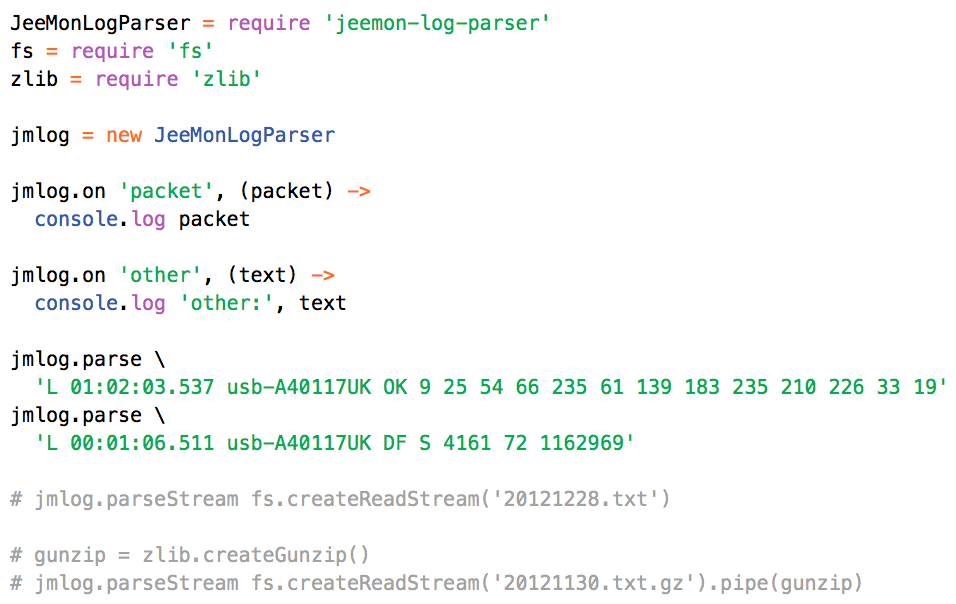
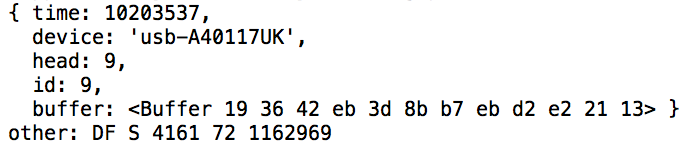
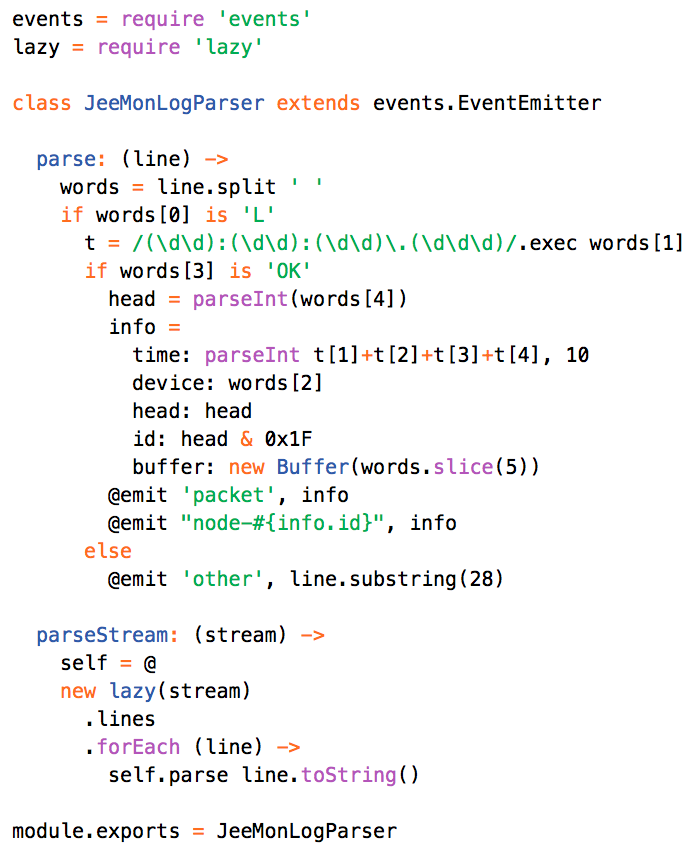
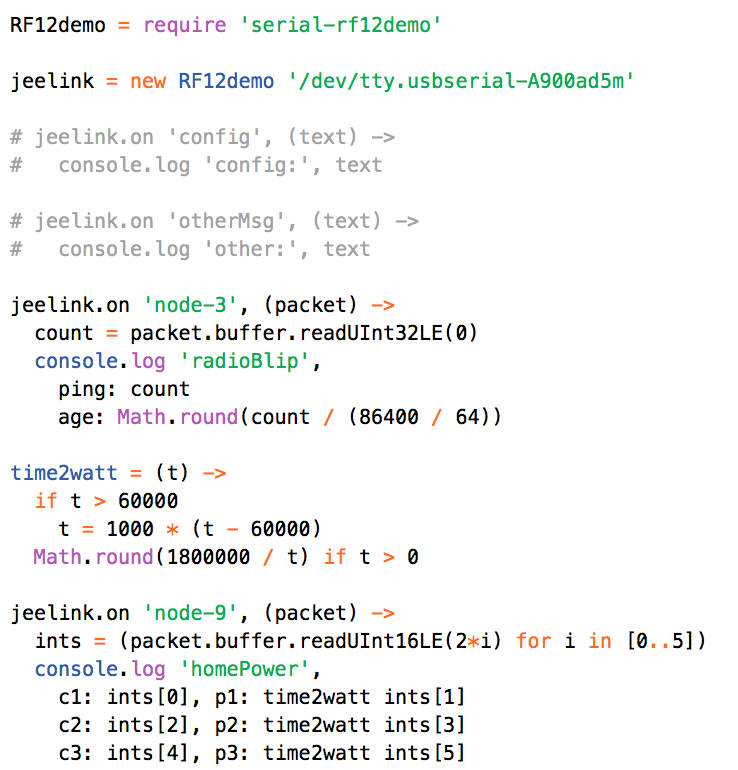
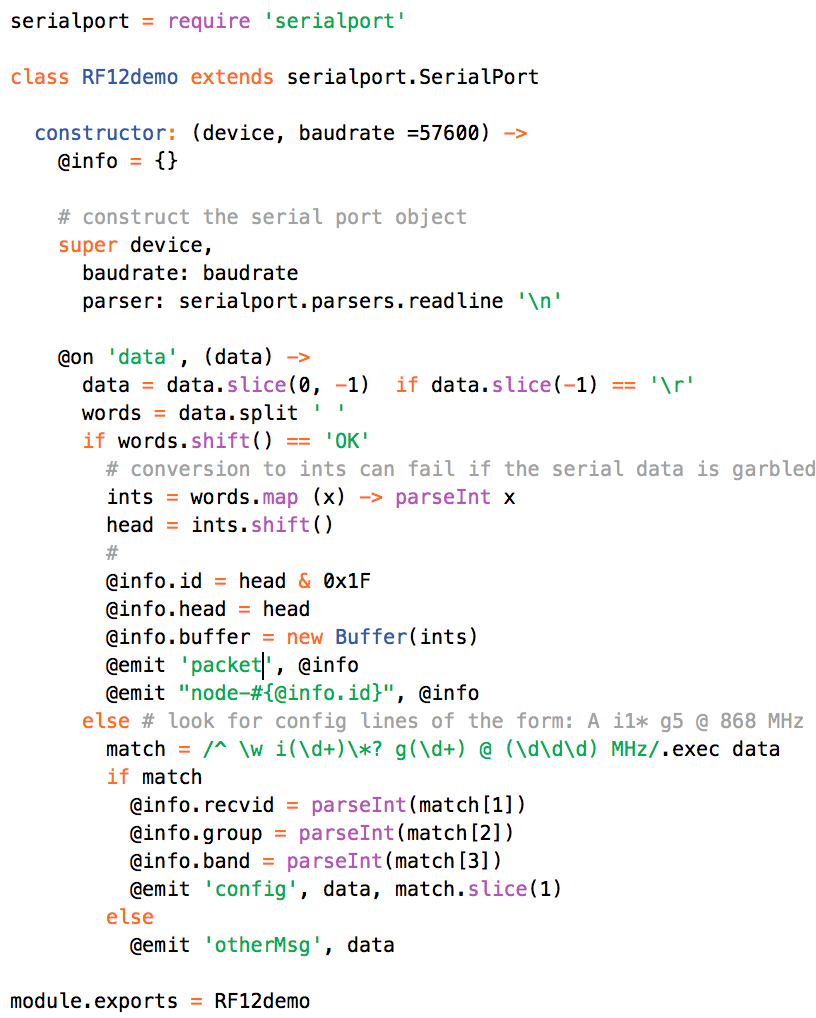
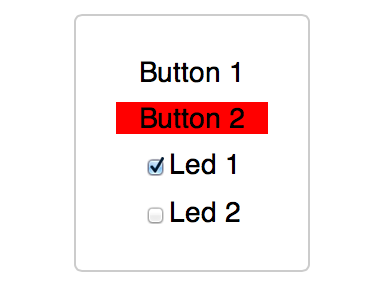

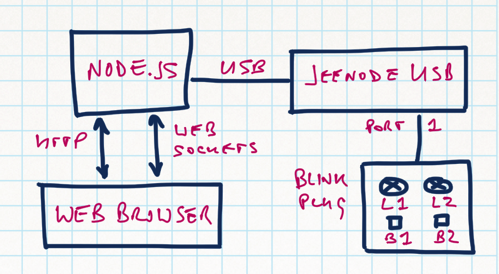
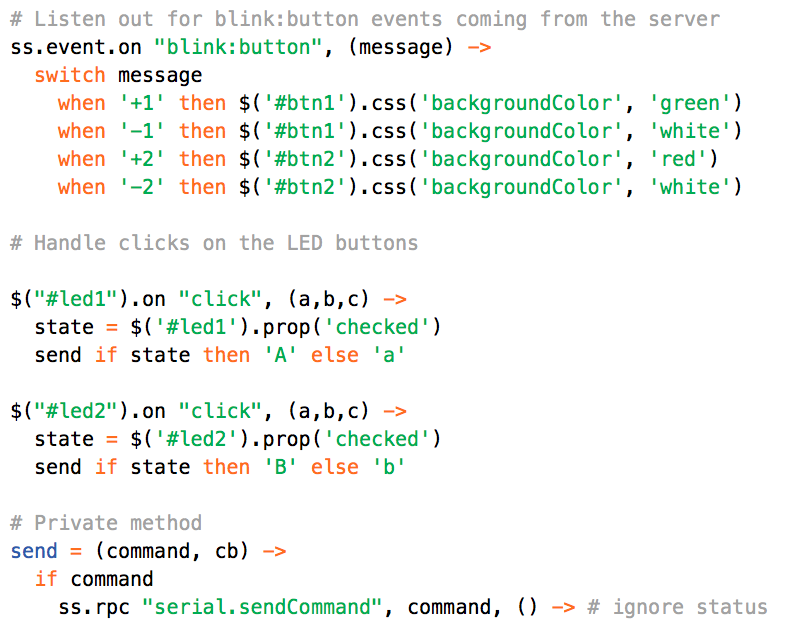
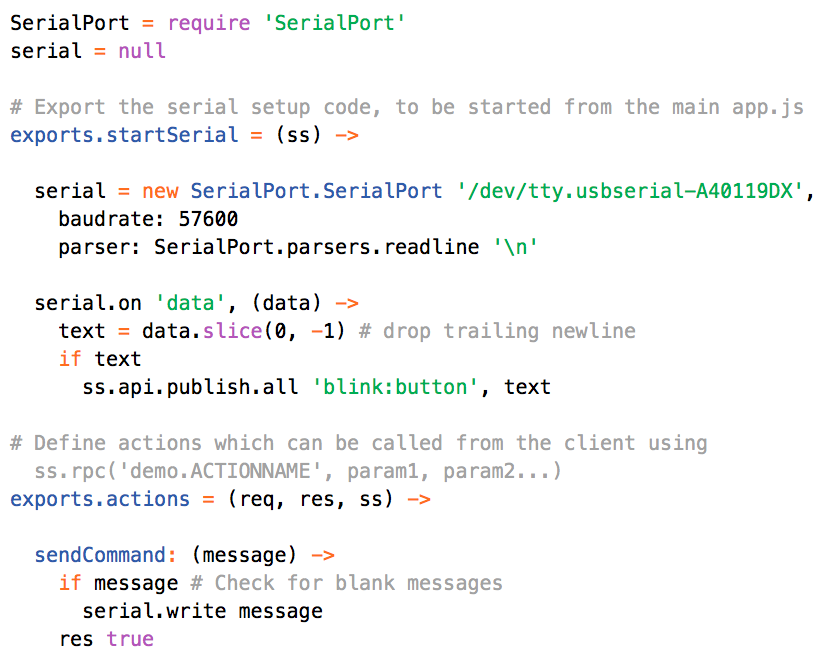
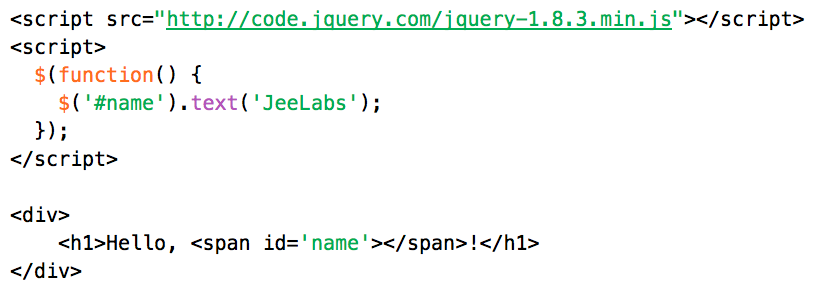





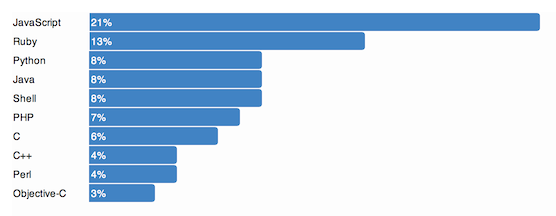




























































































































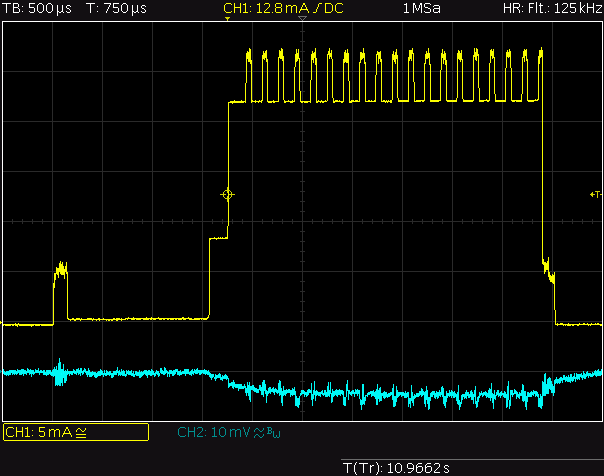





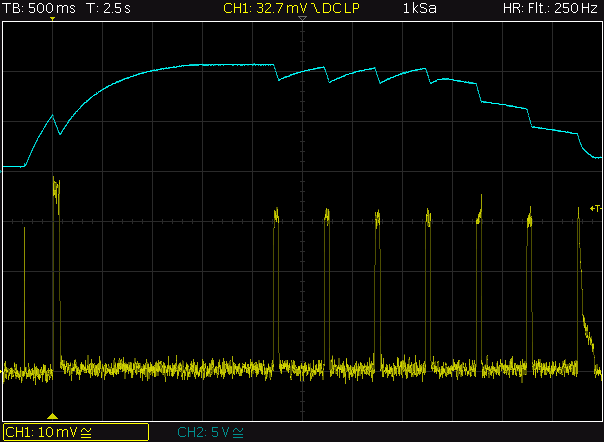
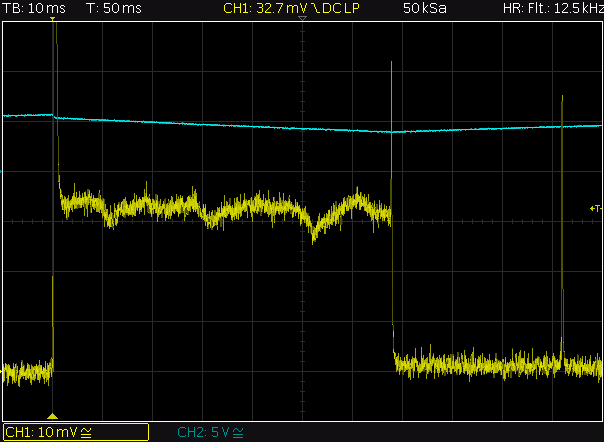


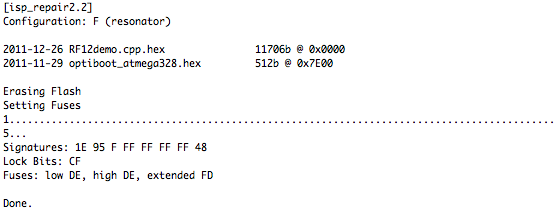
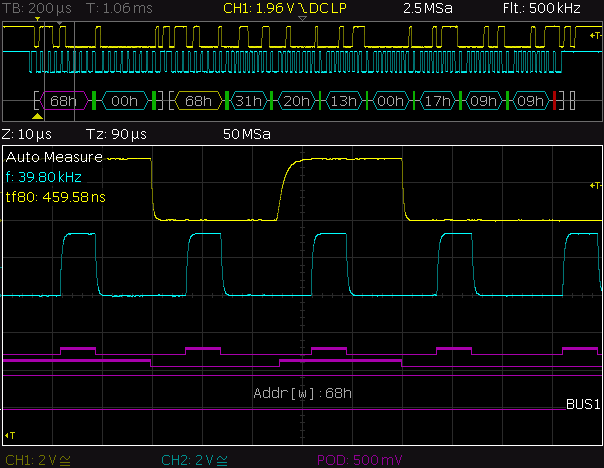

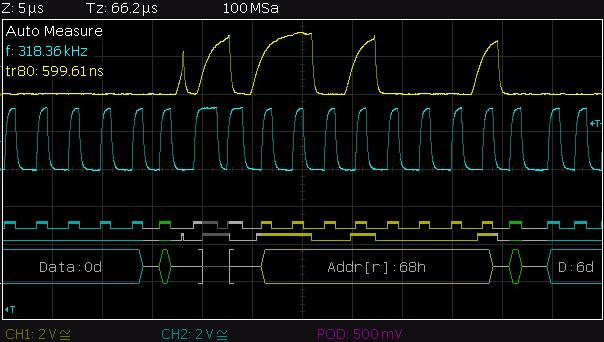
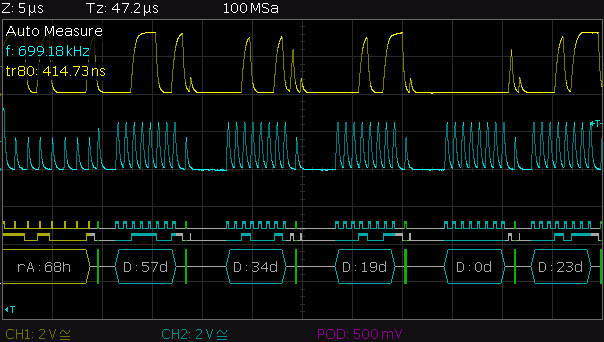






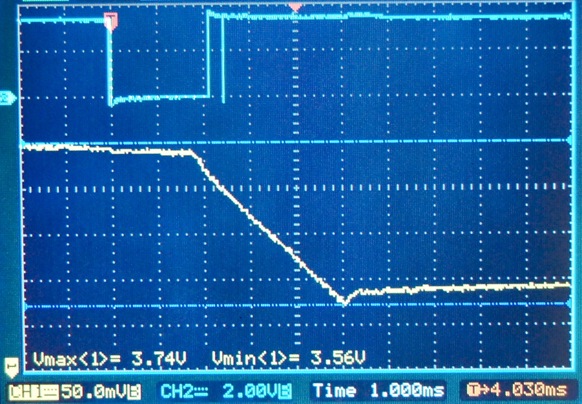
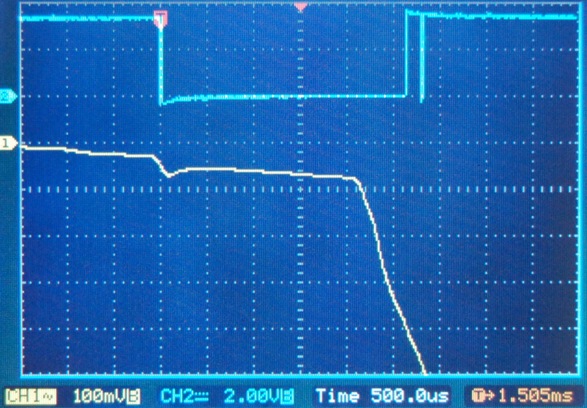
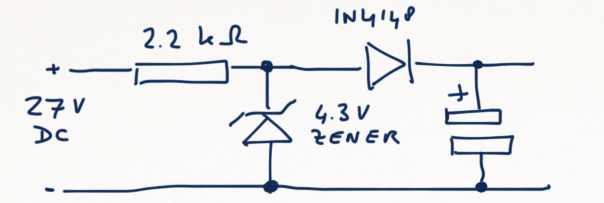
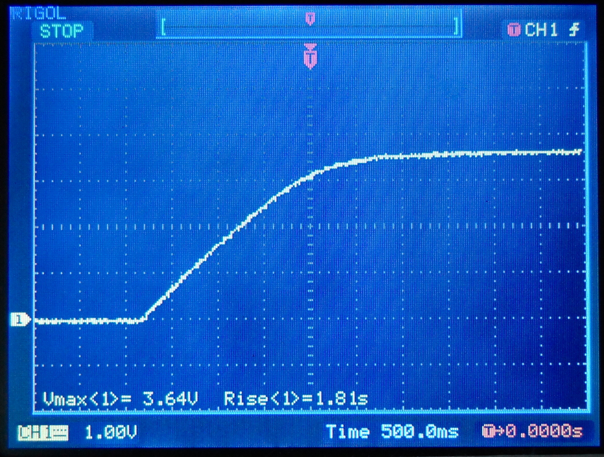
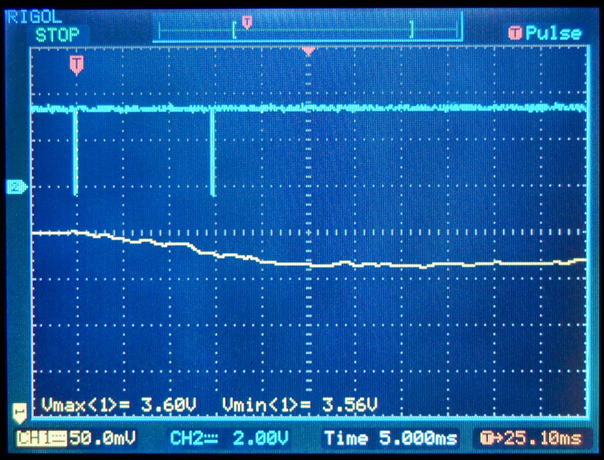

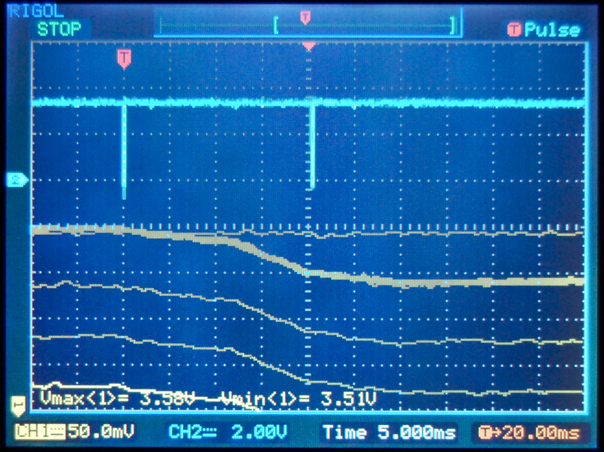
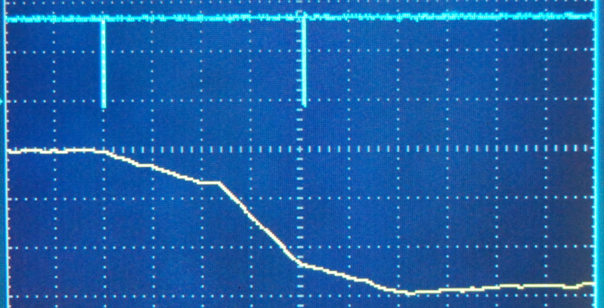
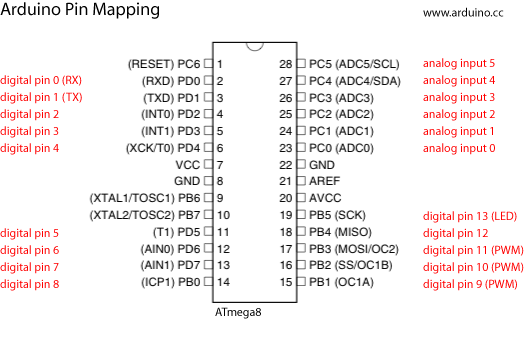
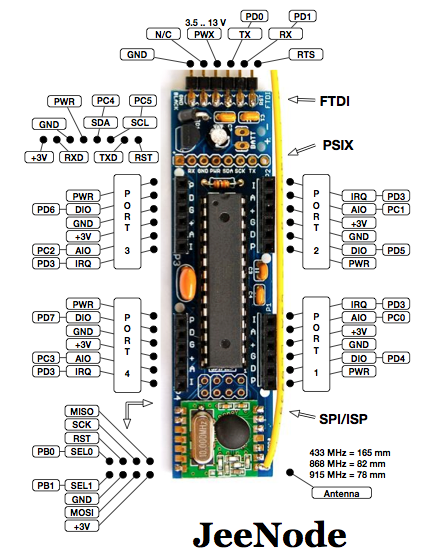
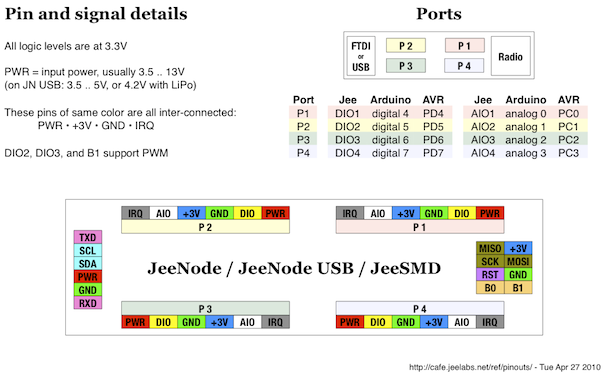
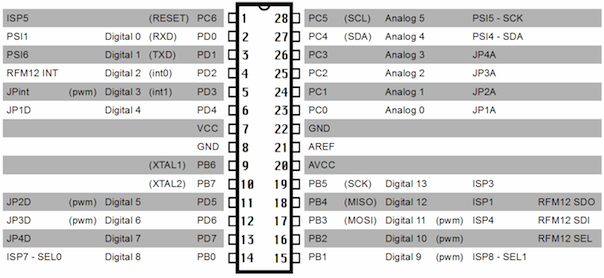

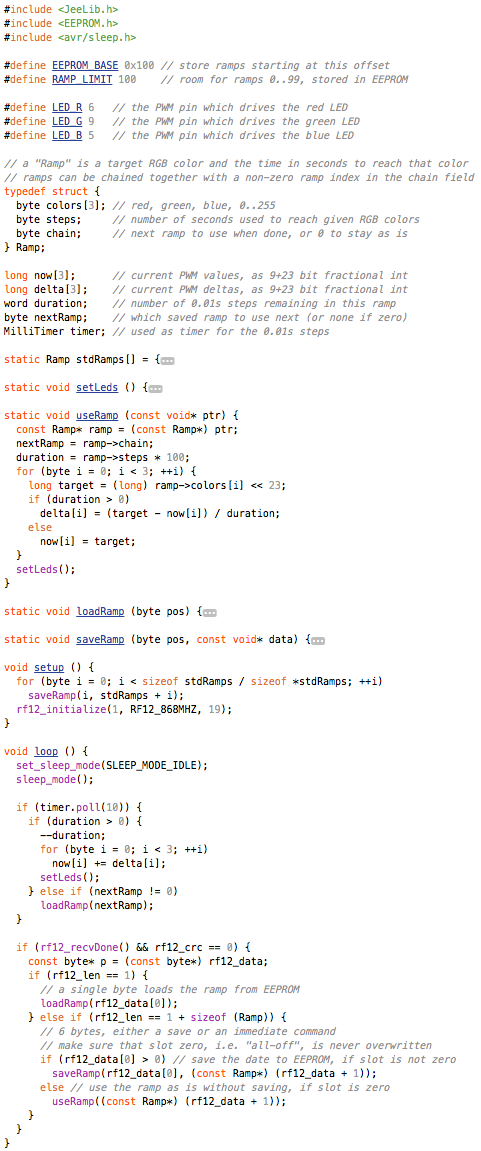




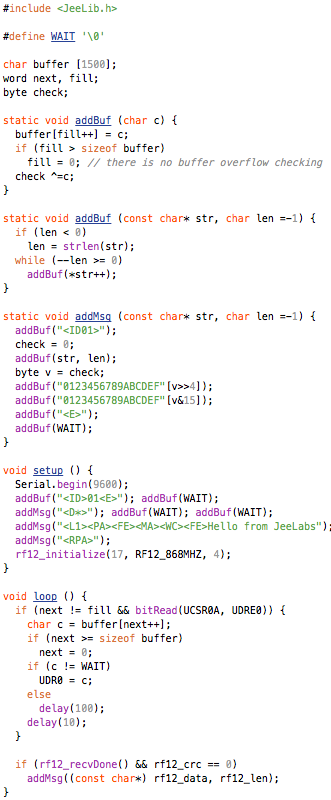




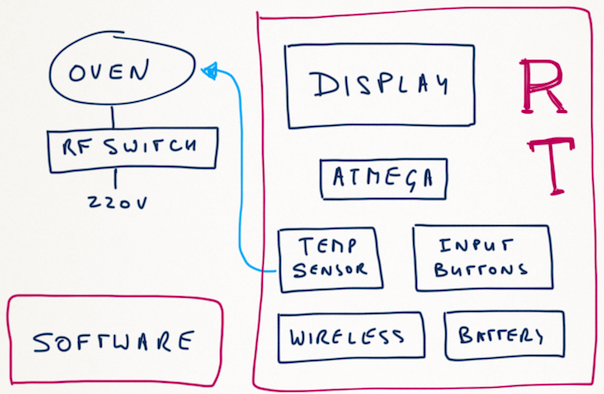
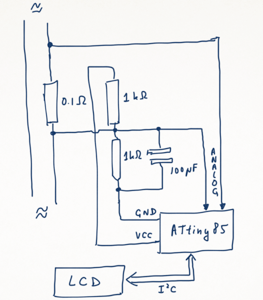
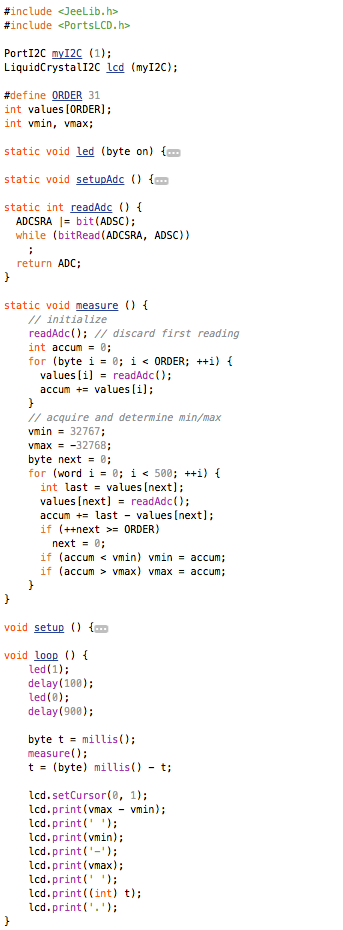










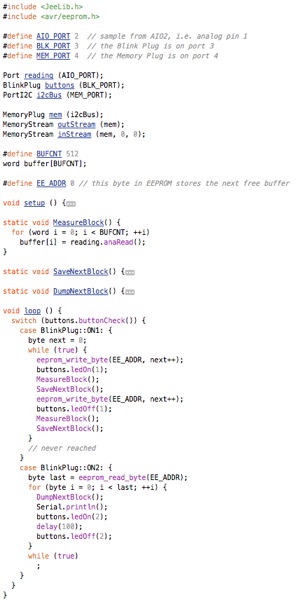



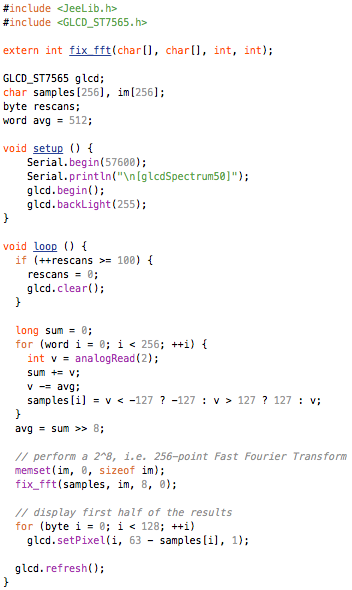




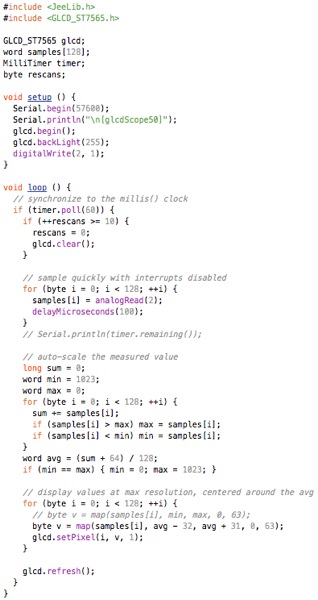





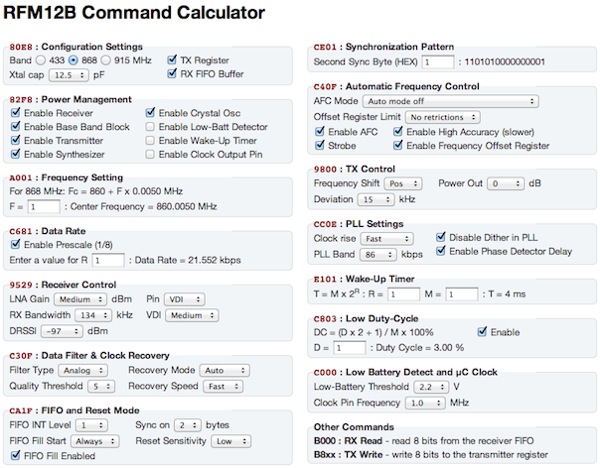
























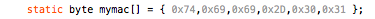
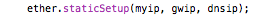





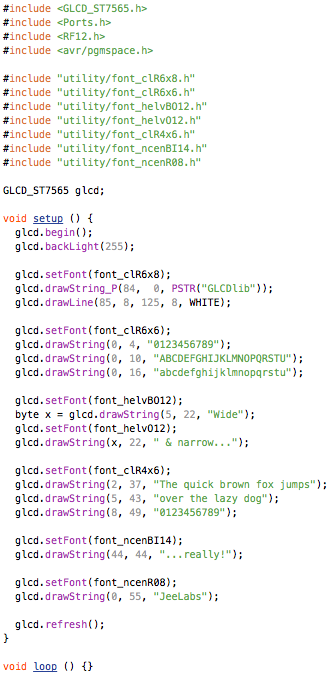








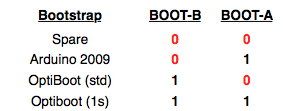
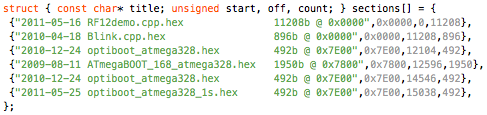
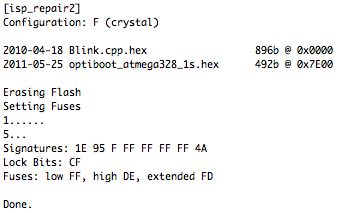





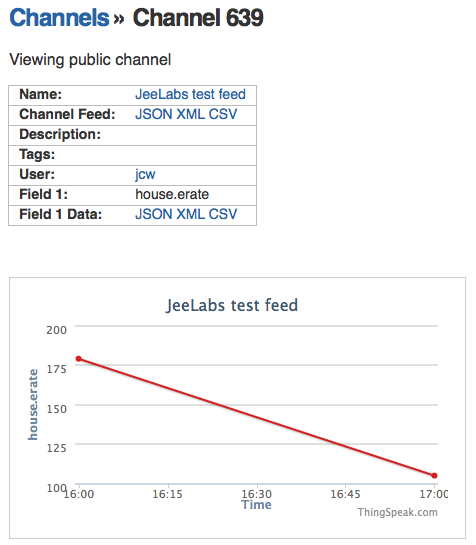

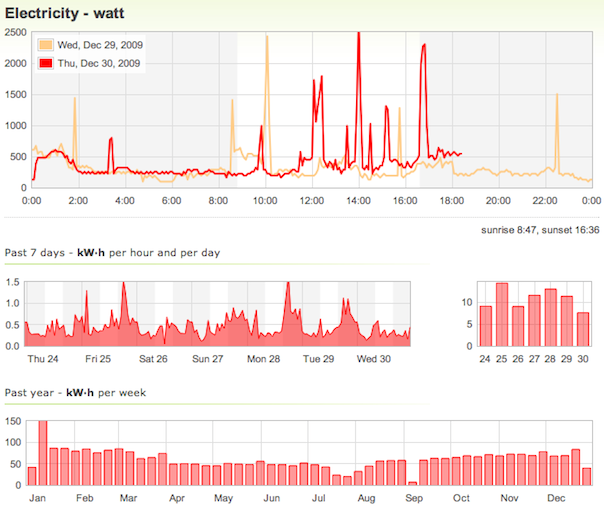
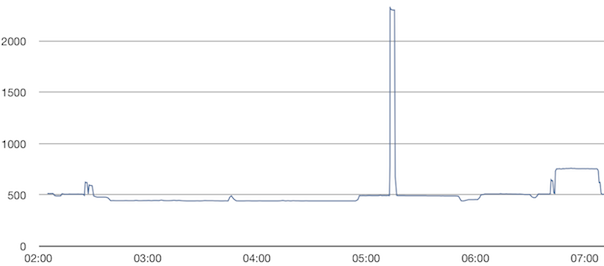
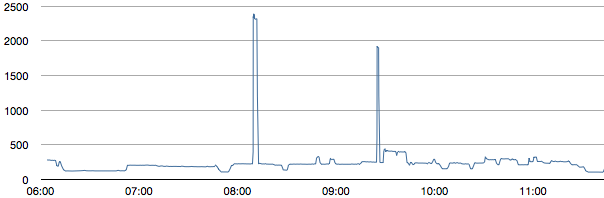





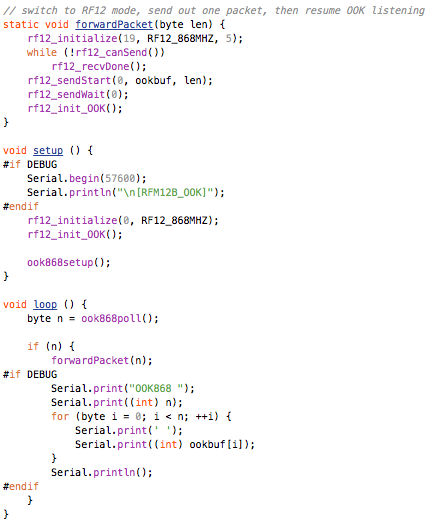


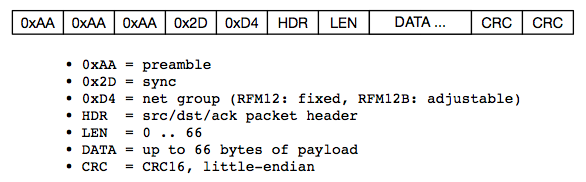

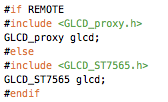














































































































































































































































































































































































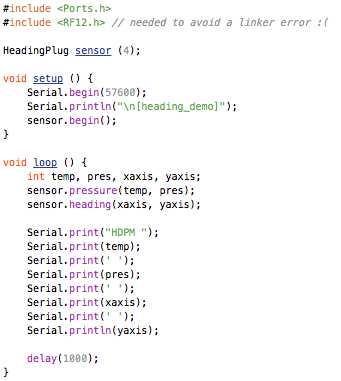




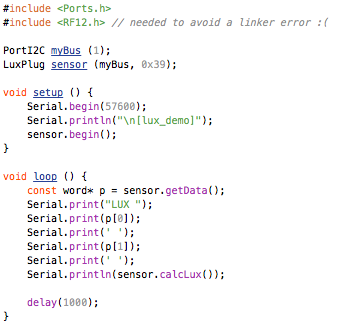


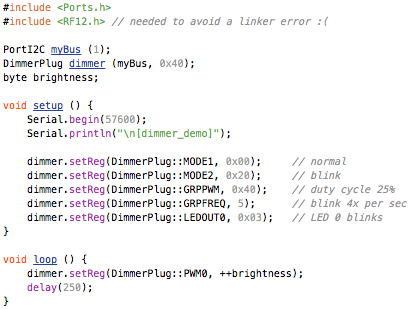



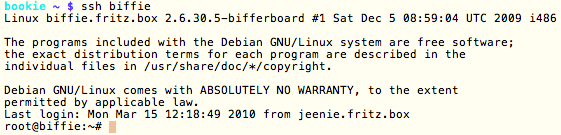
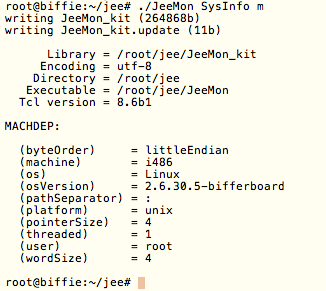




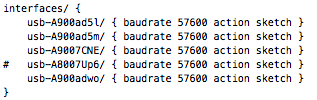


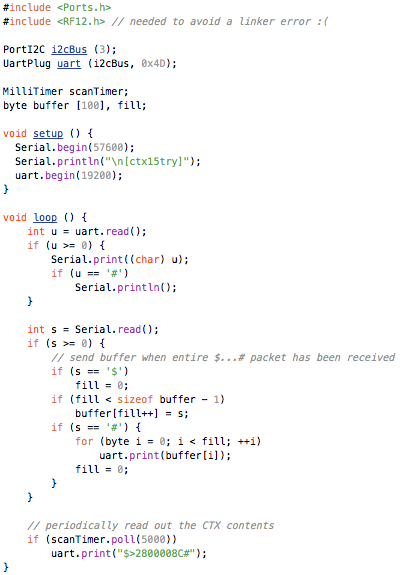
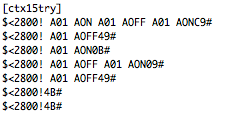

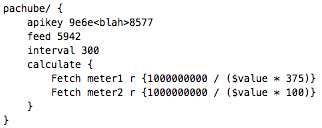

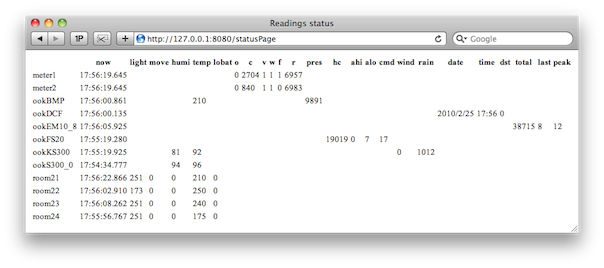
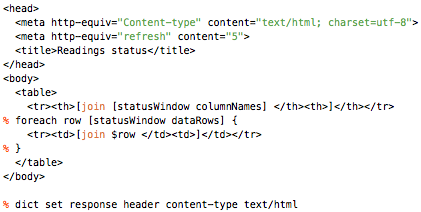
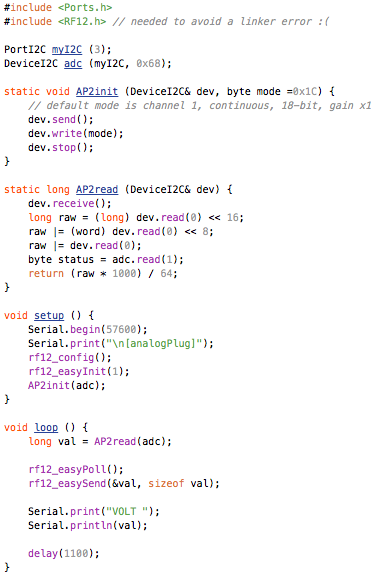
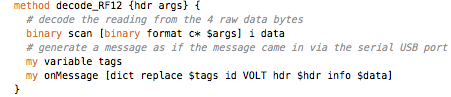
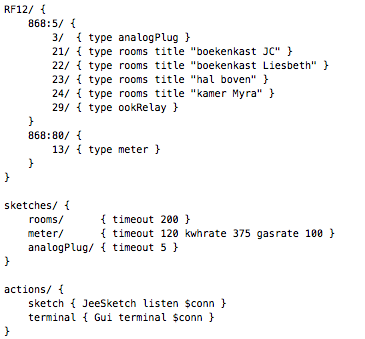

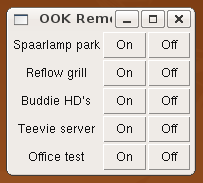
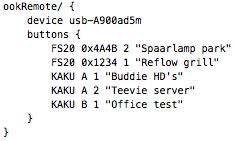
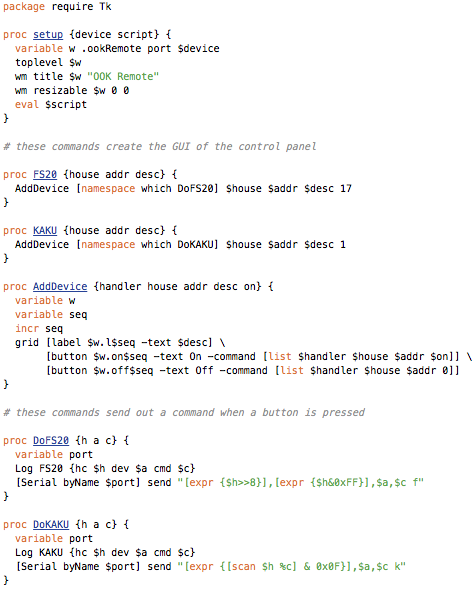
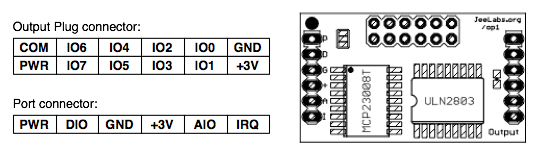
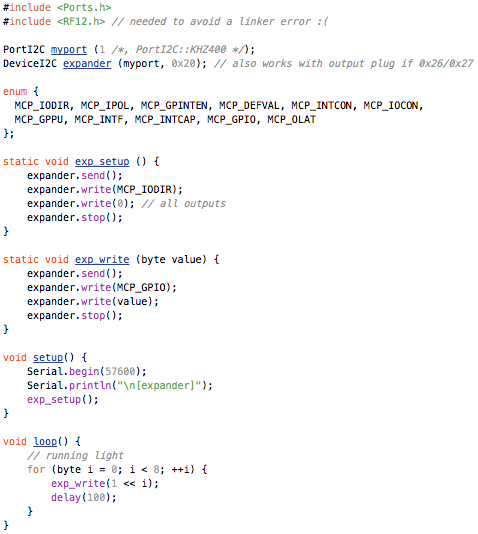

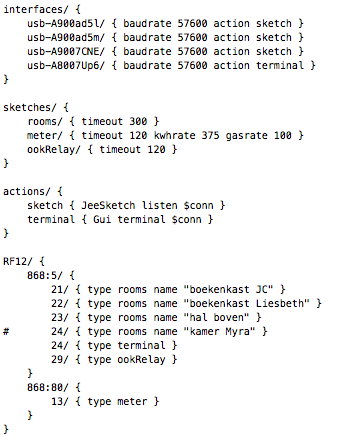
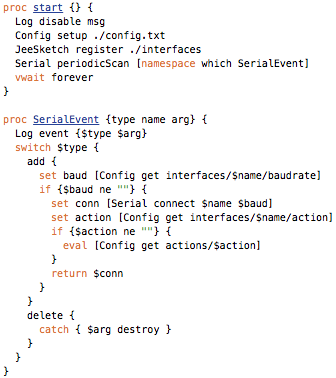
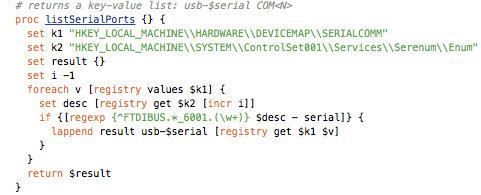





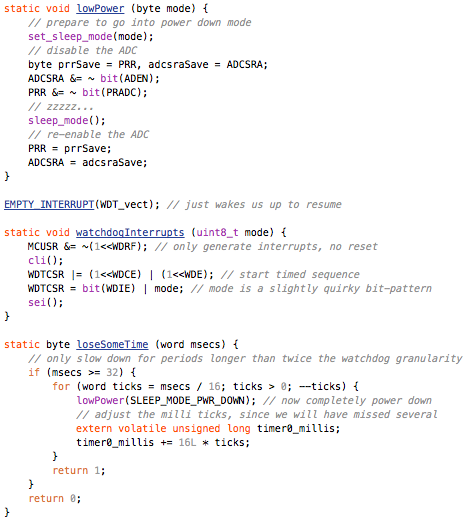

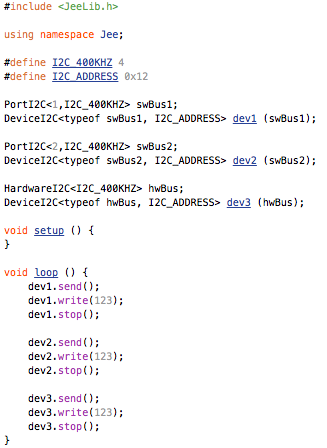

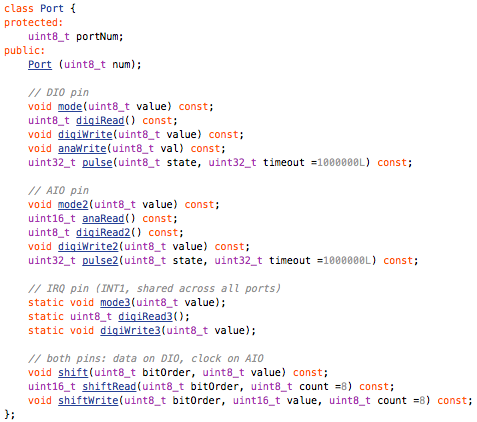


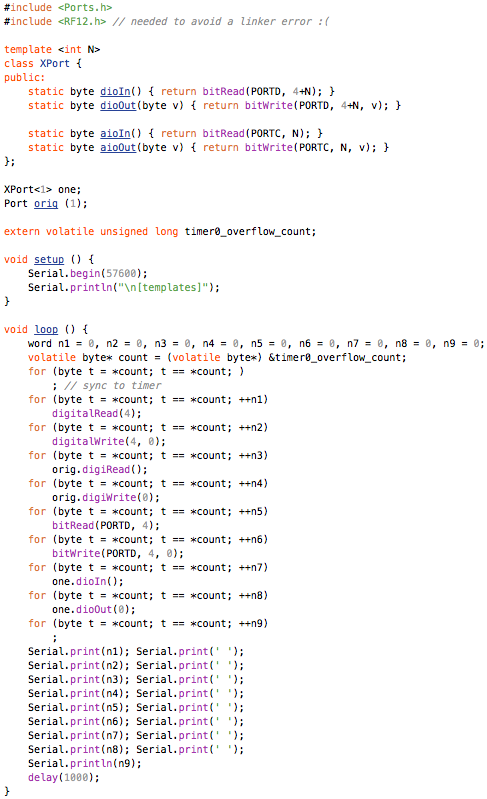
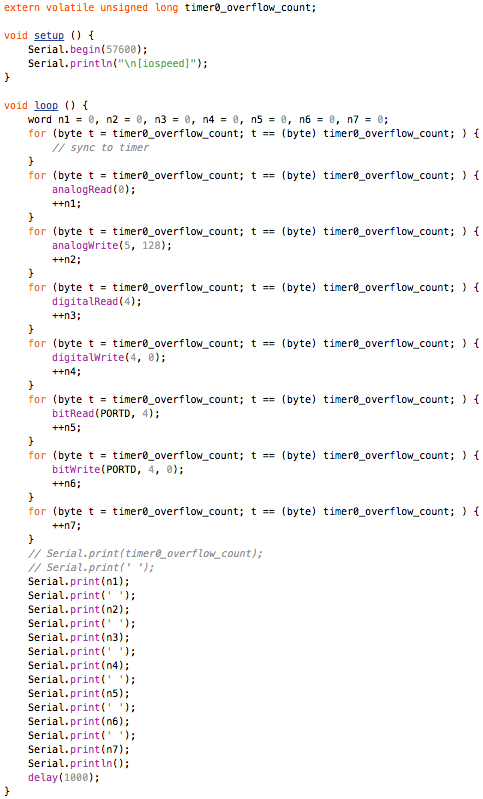
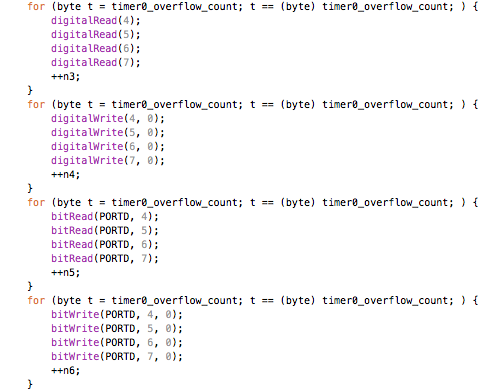
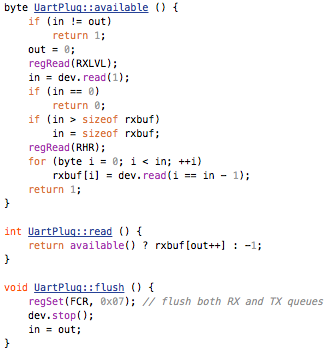

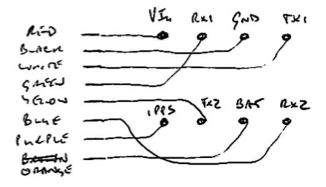

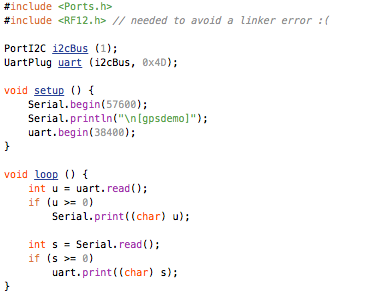









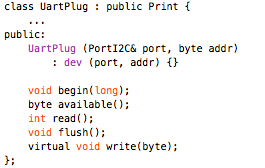
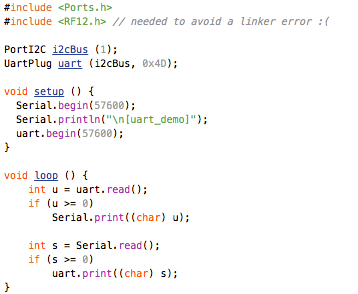

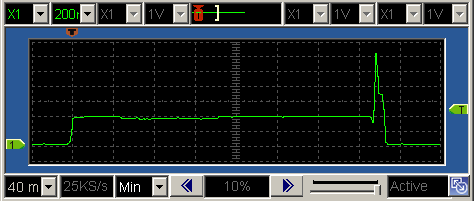




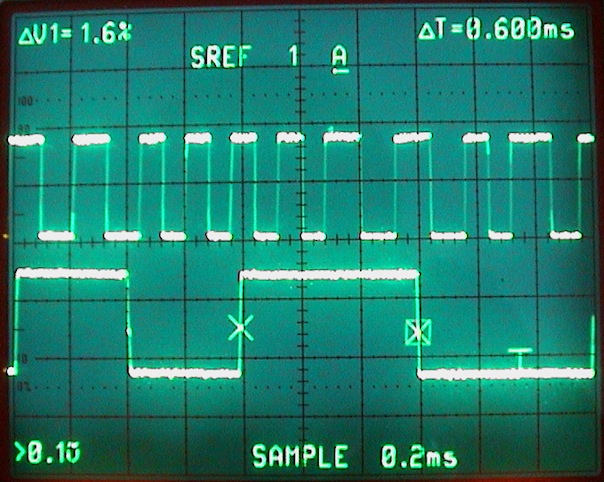
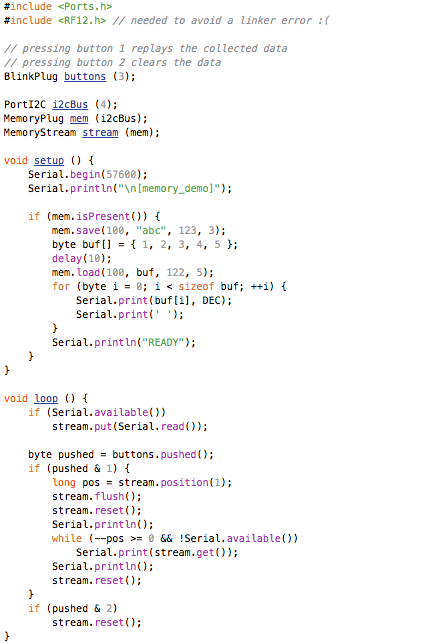
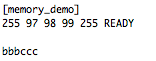
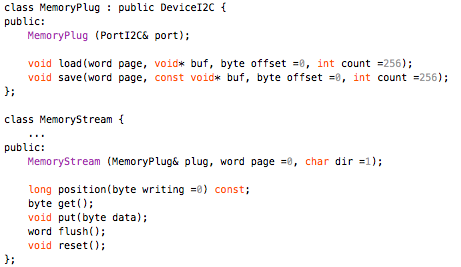
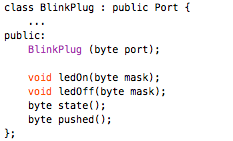

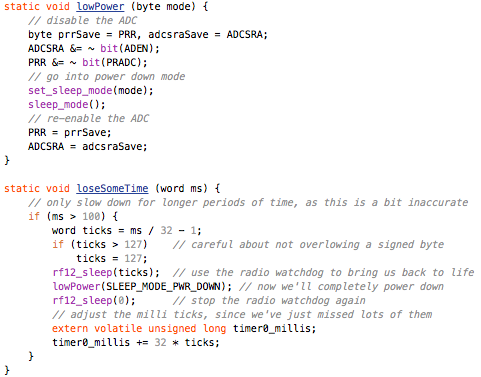



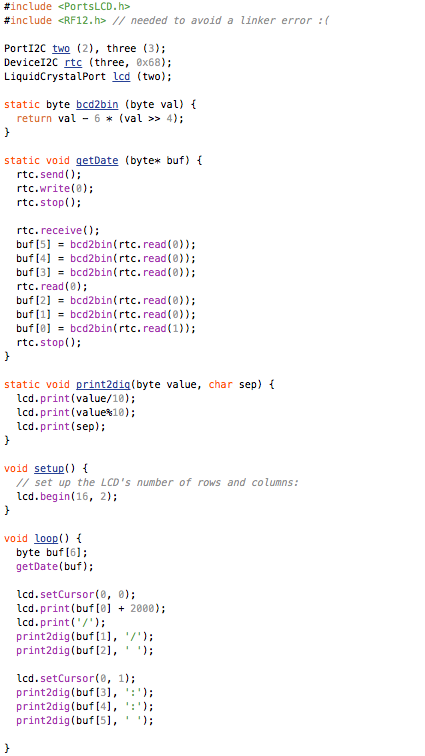




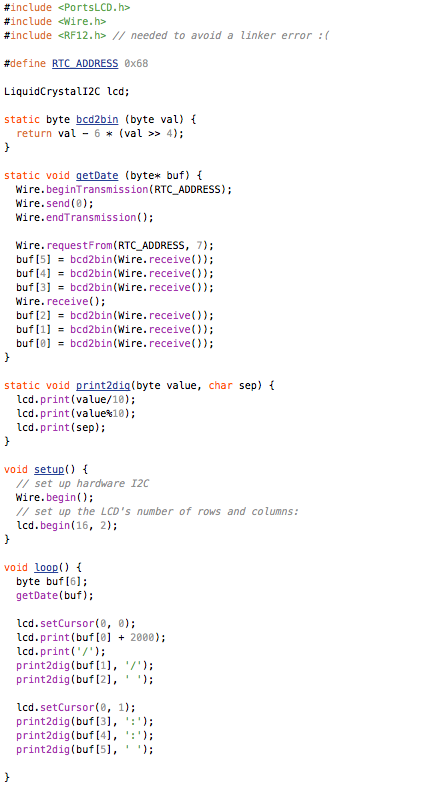






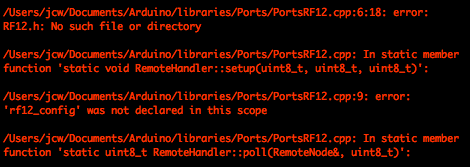


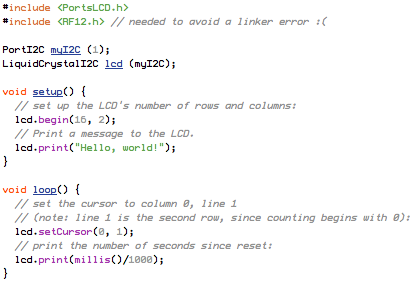
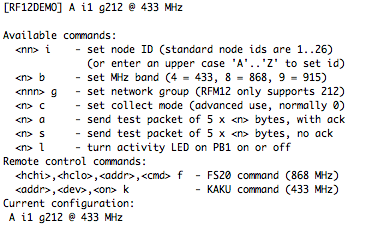
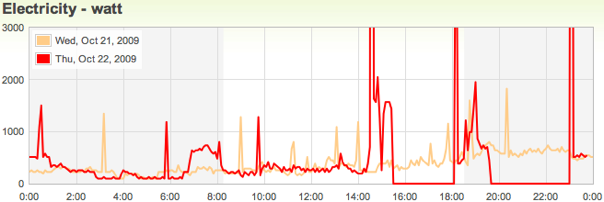
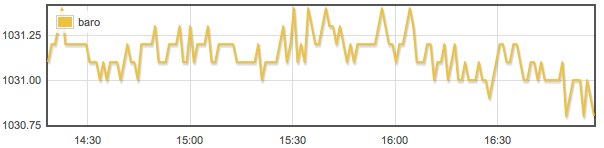
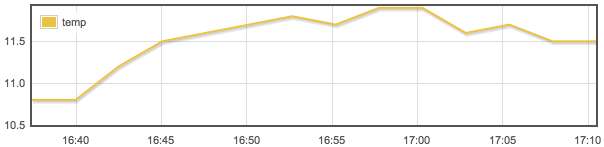



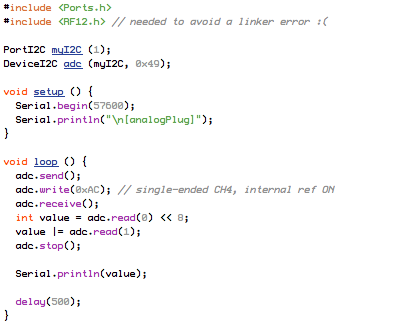








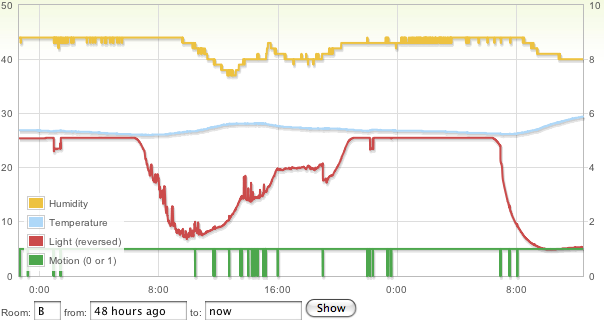

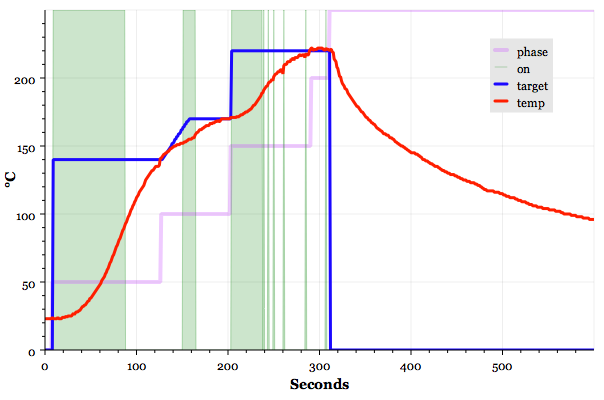
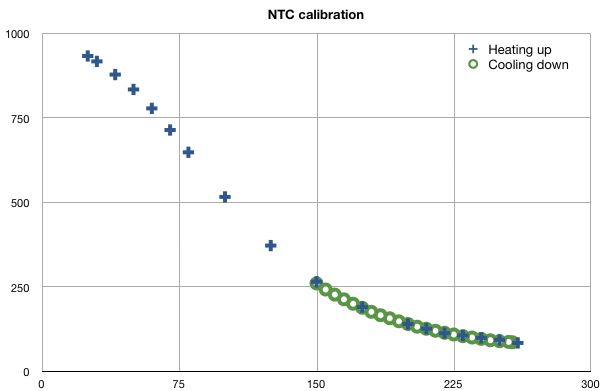
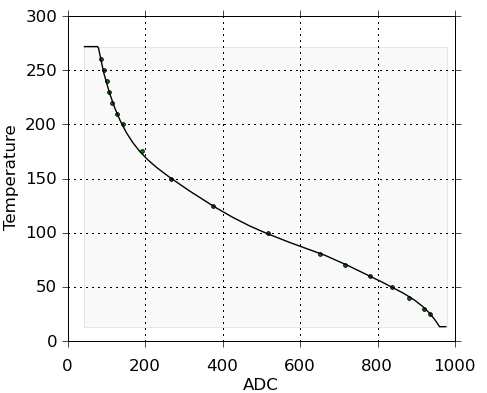
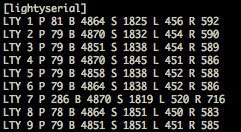


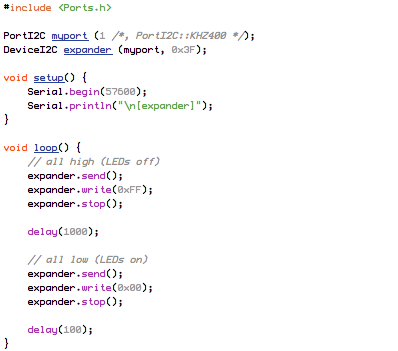
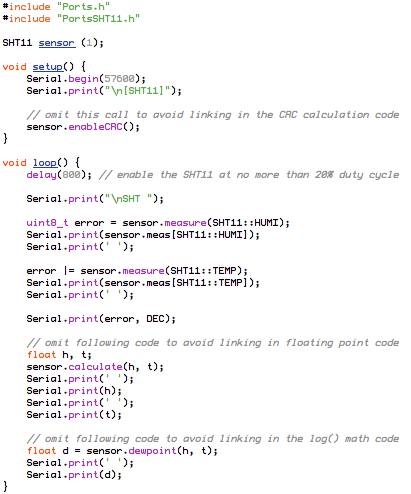
 This is a JeePlug filled to the rim with tiny components and connectors. It’s based on a PCA8574A I2C 8-bit I/O expander. Each of 8 pins can be used either as inputs or as “mostly” open collector outputs. See the datasheet for details.
This is a JeePlug filled to the rim with tiny components and connectors. It’s based on a PCA8574A I2C 8-bit I/O expander. Each of 8 pins can be used either as inputs or as “mostly” open collector outputs. See the datasheet for details.




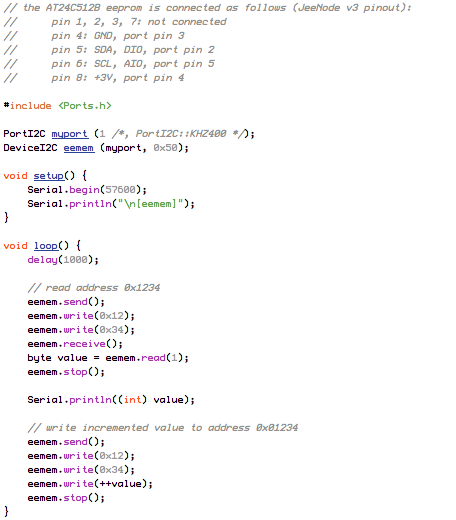
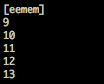
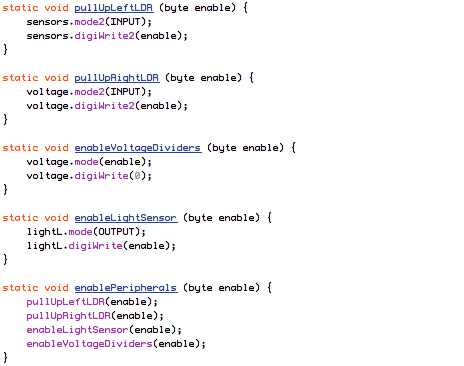




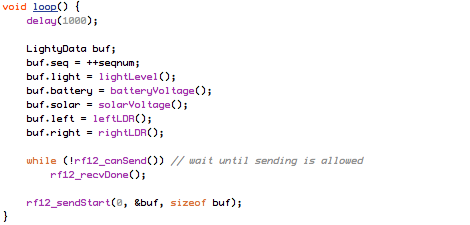

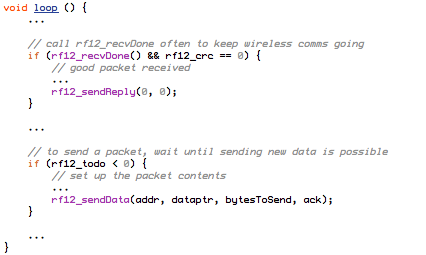
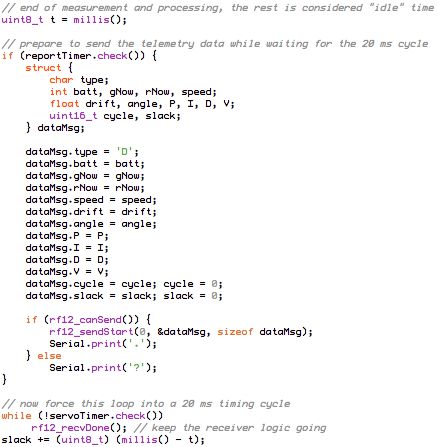

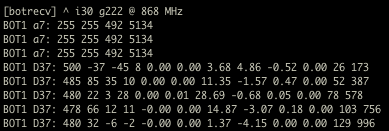


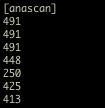

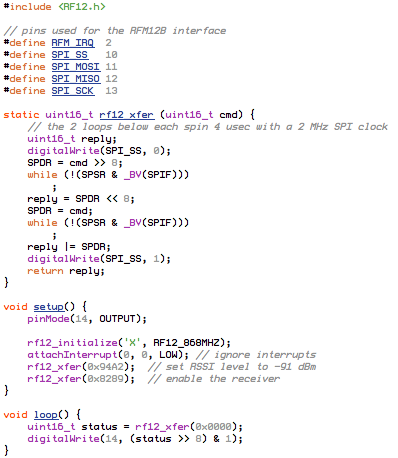




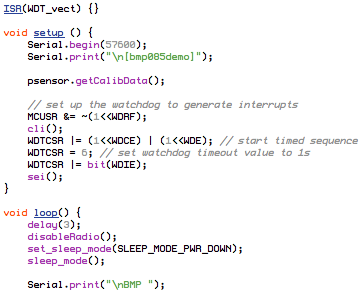


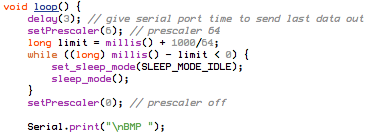



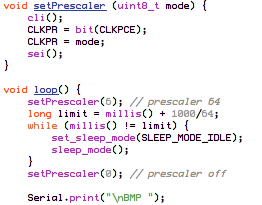

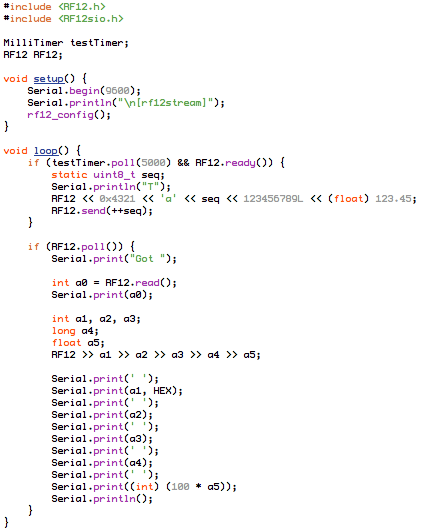
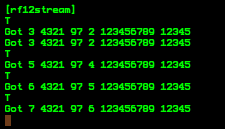
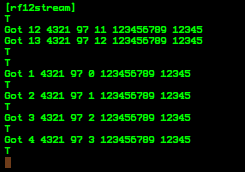
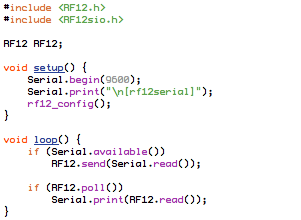
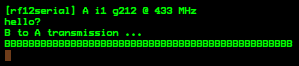
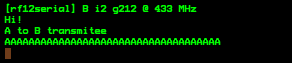
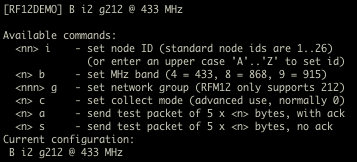







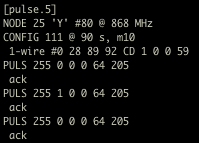

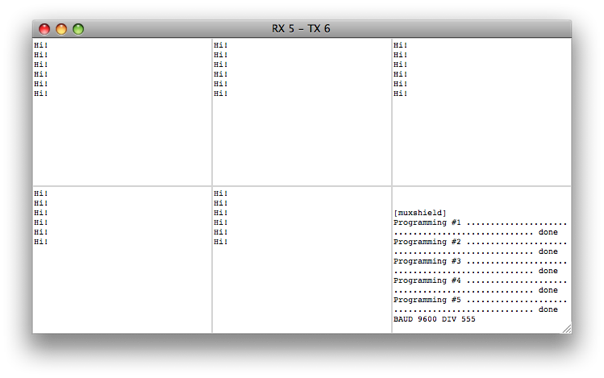
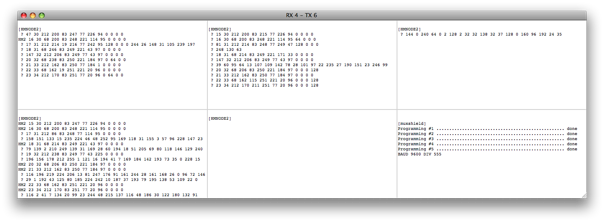

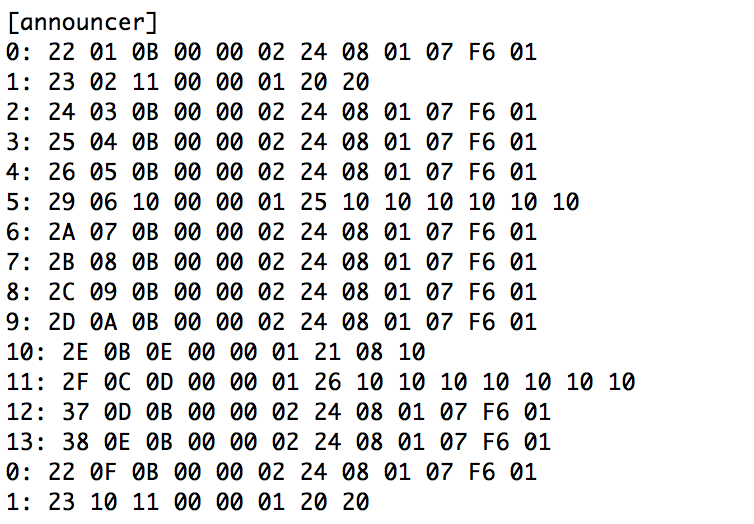
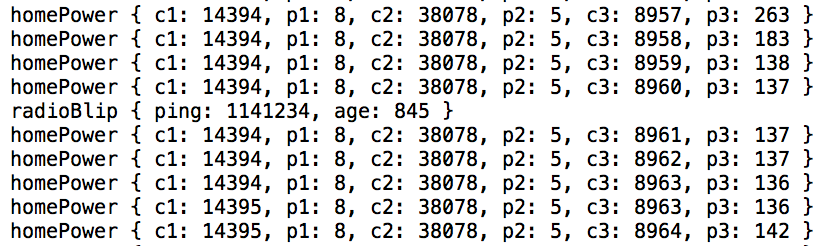
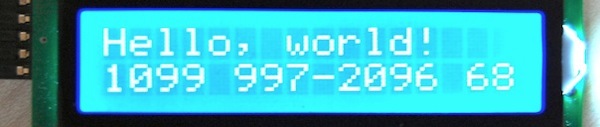
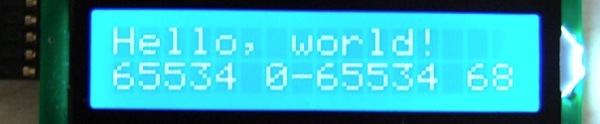
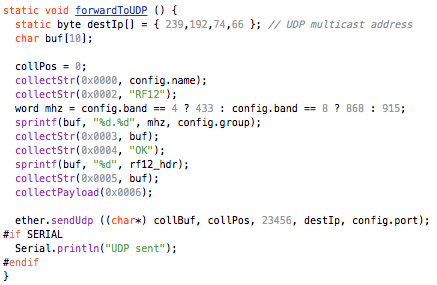
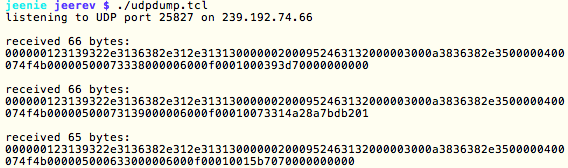
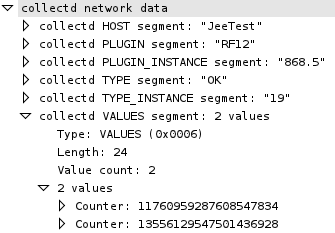
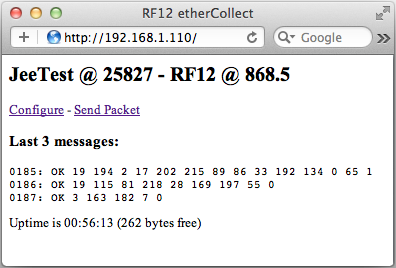
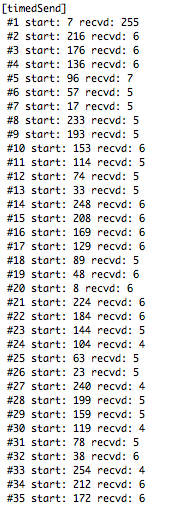
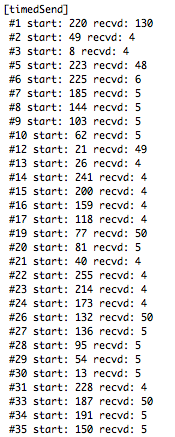
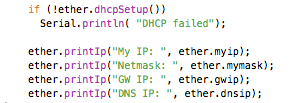
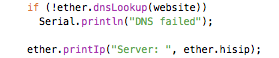
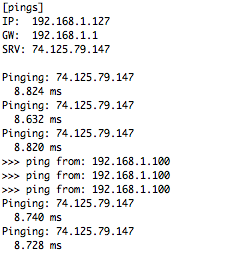
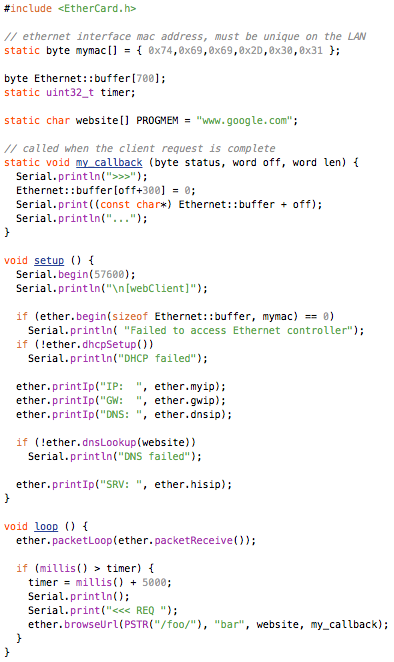
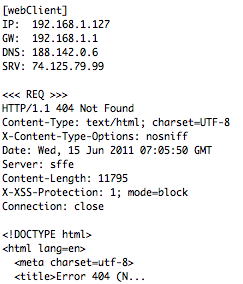
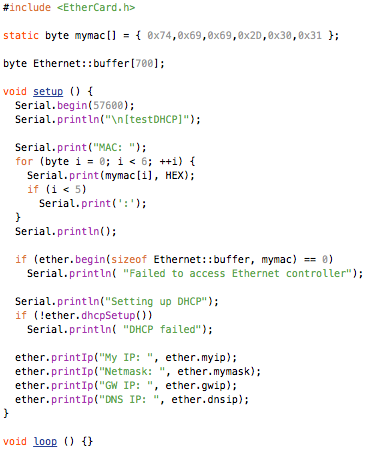
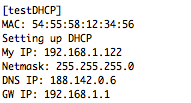
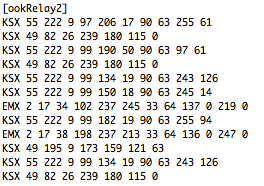
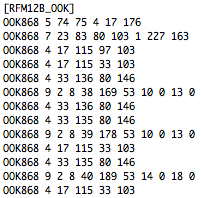
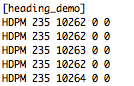
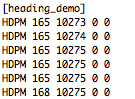
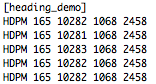
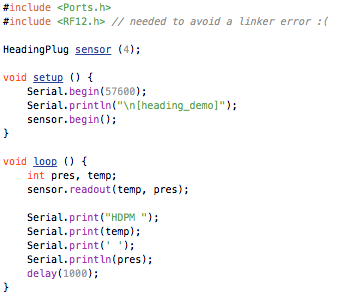
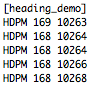
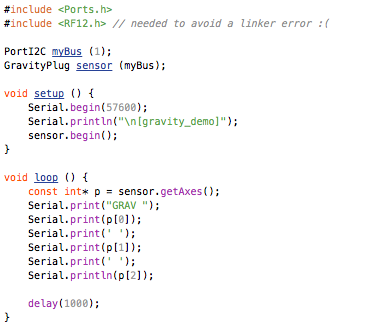
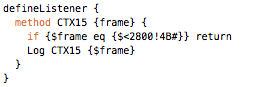
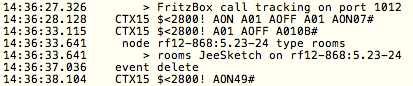
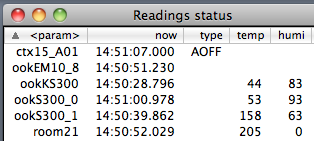
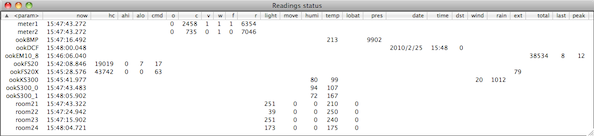
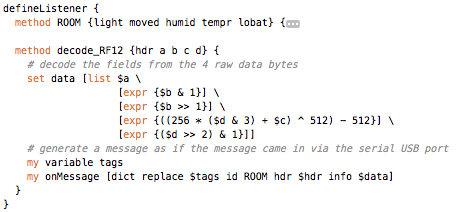
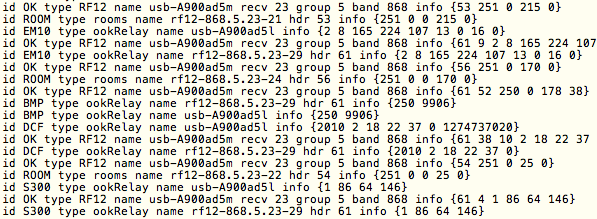
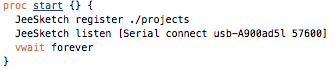
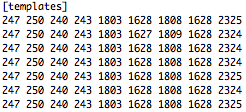
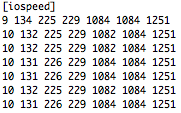
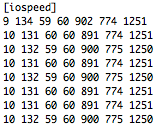
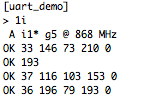
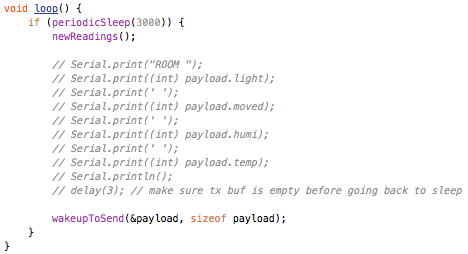
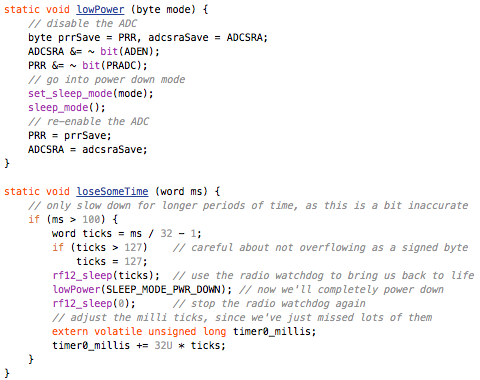
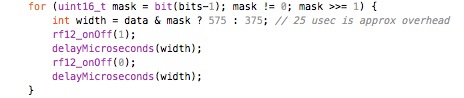
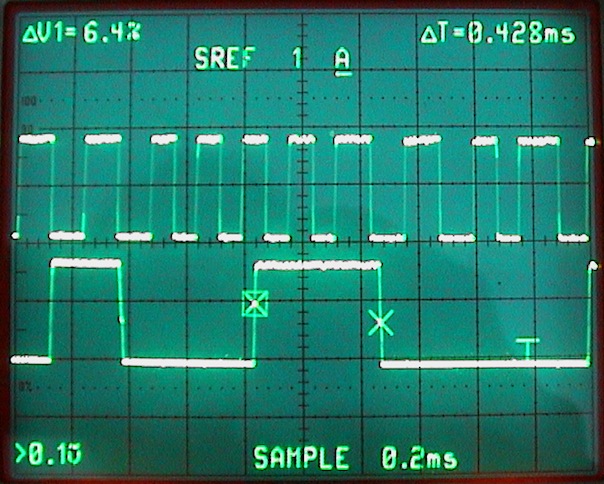
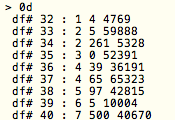
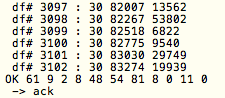
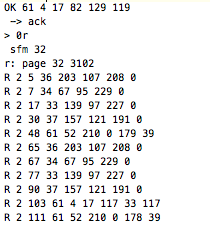
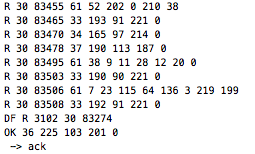
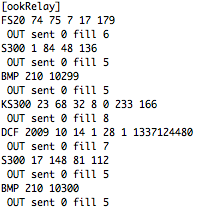
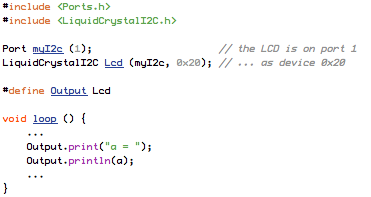
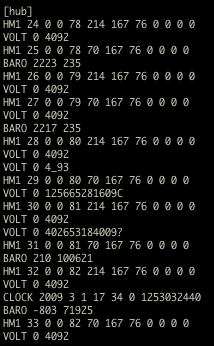
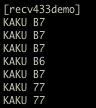
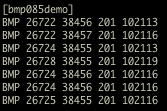
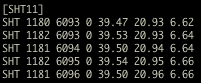
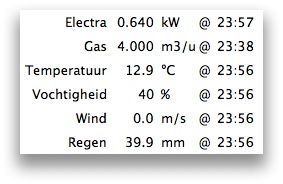
 (that’s 3x two lines of output, every 3 seconds)
(that’s 3x two lines of output, every 3 seconds)





























{kind=link}
{kind=link}
{kind=link}
{kind=link}